1. 概述
推荐系统中的算法通过用户的历史行为数据挖掘用户的偏好,实现对用户偏好的建模,从而达到为用户推荐用户感兴趣的item。用户的兴趣偏好通常是多变的,而且是多样的。然而传统的基于item的协同过滤模型只能考虑用户的静态兴趣,而不能捕获用户的兴趣偏好的动态变化。
序列深度匹配(Sequential Deep Match,SDM)模型是在特定场景下提出的用于对用户动态兴趣偏好建模的算法。SDM模型应用于淘宝的场景中,在淘宝的场景中,用户的行为主要分为两种,第一个是当前的浏览Session,用户在一个Session中,需求往往是十分明确的。另一个是之前的历史行为,一个用户虽然可能不是每次都来买球鞋,但是也可能提供一定的有用信息。因此需要分别对这两种行为序列建模,从而刻画用户的兴趣。
综上,序列深度匹配SDM通过组合用户短期Session和长期行为捕获用户的动态兴趣偏好,实现对用户兴趣的建模。
2. 算法原理
序列深度匹配SDM的模型结构如下图所示:

其中,对于用户u,通过对长期行为Lu,得到向量pu,对短期行为Su建模得到向量stu,并通过fusion gate策略将两部分组合在一起,从而得到向量otu∈Rd×1,该向量便是用户的兴趣向量。
假设V∈Rd×∣I∣为item的embedding向量,其中∣I∣为item的总数,d为embedding的维数。目标是在t+1时刻预测top N的候选集,候选集是基于otu和每个物品对应的向量vi计算匹配分数,并根据分数高低进行召回,分数的计算方法为:
zi=score(otu,vi)=otuTvi
2.1. 长短期Session的划分
对于用户行为序列的划分,文章中给出了按照session的划分规则:
- 具有同样的Session ID的记录为同一个Session;
- Session ID不同,但是相邻的行为间隔小于10min,算同一个Session;
- Session的最大长度为50,超过50的划分到新的Session。
基于上述的Session划分规则,用户u最近一个Session的行为被认为是短期行为,表示为:
Su=[i1u,⋯,itu,⋯,imu]
其中,m为序列的长度,而用户的长期行为序列为Su之前的7天的行为,记为Lu。
2.2. item和user的Embedding表示
在构建item的embedding时,不仅考虑到ID特征,同时还包括了leaf category,first level category,brand和shop等side information,最终item的向量表示为
eitu=concat({eif∣f∈F})
同样的,用户也有对应的属性,如age,gender,life stage。最终user的向量表示为
eu=concat({eup∣p∈P})
2.3. 短期行为建模
短期行为建模的整体过程如下图所示:

短期行为是用户在最近的一个Session里的行为。短期行为建模分为三个部分,分别为LSTM建模,Multi-head Self-Attention建模和User Attention。
2.3.1. LSTM
在将物品转换为Embedding向量后,首先通过LSTM来进行建模,LSTM的建模过程如下图所示:

对于给定的的用户短期行为序列[ei1u,⋯,eitu],通过LSTM建模的结果为:
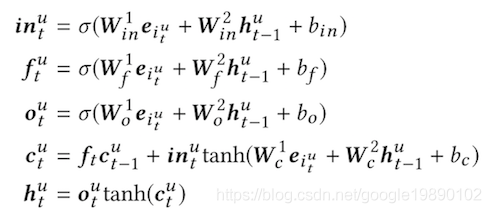
其中,intu,ftu,otu分别表示输入门,遗忘门和输出门。htu∈Rd×1表示的是LSTM在t时刻隐藏层的输出。
2.3.2. Multi-head Self-Attention
在经过LSTM对短期行为序列建模后,得到所有隐含层的输出Xu=[h1u,⋯,htu]。接下来,使用Multi-head Self-Attention对此行为序列建模,目的是能够捕获到用户多种类型的兴趣。Multi-head Self-Attention的建模过程如下所示:

假设Multi-head Self-Attention建模后的结果为X^u=[h^1u,⋯,h^tu],则X^u可以表示为:
X^u=MultiHead(Xu)=WOconcat(head1u,⋯,headhu)
其中,WO∈Rd×hdk,h表示head的个数,dk=h1d。对于每一个headiu∈Rdk×t表示
每一个兴趣,其计算方法为:
headiu=Attention(WiQXu,WiKXu,WiVXu)
其中,WiQXu,WiKXu和WiVXu分别表示上图中的Q,K,V。令Qiu=WiQXu,Kiu=WiKXu,Viu=WiVXu,则headiu为:
headiu=ViuAiuT
其中,Aiu=softmax(QiuTKiu)。
2.3.3. User Attention
对于不同的用户,即使短期的行为序列是一样的,也可能会存在不同的兴趣偏好,为了能够更精准的挖掘用户偏好,使用Attention机制计算不同用户兴趣的偏好,Attention机制如下图所示:

对于用户的多种兴趣X^u=[h^1u,⋯,h^tu],通过与用户向量eu计算t时刻的兴趣偏好向量stu
stu=k=1∑tαkh^ku
其中αk=∑k=1texp(h^kuTeu)exp(h^kuTeu)。
2.4. 长期行为建模
对于长期行为序列,文章中提出从不同角度来刻画用户的兴趣,比如品牌,类别等。因此把长期行为中的所有物品对应的属性集合Lu={Lfu∣f∈F}划分为不同的子集合,如ID子集合Lidu、leaf category子集合Lleafu,first level category子集合Lcateu,shop子集合Lshopu、brand子集合Lbrandu。下图展示了长期行为的建模过程:
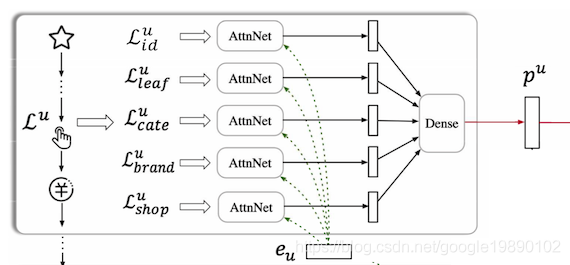
通过AttnNet计算在每个子集合上的向量zfu
zfu=k=1∑∣Lfu∣αkgku
其中,gku=Wffku∈Rd×1,αk=∑k=1∣Lfu∣exp(gkuTeu)exp(gkuTeu)。
最终,将zfuconcat在一起输入到全连接网络中,得到长期兴趣pu=tanh(Wpzu+b),其中zu=concat({zfu∣f∈F})。
2.5. 兴趣融合
为了将长短期兴趣向量组合在一起,文中借鉴了LSTM中的门的概念,对短期兴趣向量和长期兴趣向量进行一个加权,过程如下:
Gtu=sigmoid(W1eu+W2stu+W3pu+b)
otu=(1−Gtu)⊙pu+Gtu⊙stu
2.6. 总结
序列深度匹配SDM通过组合用户短期Session和长期行为捕获用户的动态兴趣偏好,实现对用户兴趣的建模,完整的模型结构如下图所示:
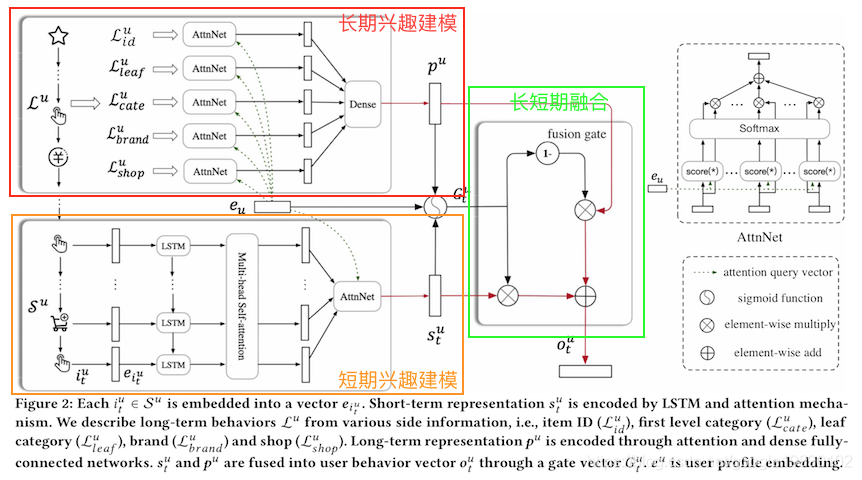
在短期兴趣建模过程中,使用LSTM,Multi-head Self-attention和User Attention建模,在长期兴趣建模过程中,使用User Attention对子集合建模,最终通过gate函数融合长短期兴趣。
3. 疑问
在本文中短期兴趣建模的过程中,作者先用LSTM建模,作者给出的理由是在之前的基于Session的推荐中,效果较好;后面使用Multi-head Self-attention建模,是为了构建用户的多个兴趣维度。这里Multi-head Self-attention也可以直接对序列建模,不知道为什么需要在这里同时使用LSTM+Multi-head Self-attention。这一点在文中并没有给出具体解释。
参考文献
[1] Lv F , Jin T , Yu C , et al. SDM: Sequential Deep Matching Model for Online Large-scale Recommender System[J]. 2019.
[2] [深度模型] 阿里大规模深度召回序列模型SDM
[3] SDM:用户长短期兴趣召回模型
[4] SDM(Sequential Deep Matching Model)的复现之路
[5] Vaswani A , Shazeer N , Parmar N , et al. Attention Is All You Need[J]. arXiv, 2017.