1. 概述
在深度学习遍地开花的今天,浅层的网络结构甚至是传统的机器学习算法被关注得越来越少,但是在实际的工作中,这一类算法依然得到广泛的应用,或者直接作为解决方案,或者作为该问题的baseline,fastText就是这样的一个文本分类工具。fastText是2016年由facebook开源的用于文本分类的工具,fastText背后使用的是一个浅层的神经网络,在保证准确率的前提下,fastText算法的最大特点是快。
2. 算法原理
2.1. fastText的模型结构
fastText是如何保证速度的呢?首先fastText的模型结构如下所示:
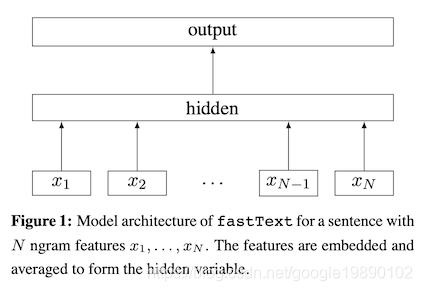
假设文本有个词,如上图所示,首先将这个词映射成词向量,可以通过矩阵实现,得到个词的向量后,将这些向量相加并取均值,得到该段文本的向量表示,最后输入到线形分类器中,得到最终的分类。从模型结构上来看,模型结构也是相当简单,只是是逻辑回归LR模型的基础上增加了句子向量的计算。对于分类问题,其损失函数为:
其中,表示的是类别,为激活函数,通常采用sigmoid函数。
2.2. 层次softmax
为了简化问题,假设隐含层的为,那么对于,其属于第个类别的概率为:
如果类别较多时,上述公式的分母的计算会严重降低算法的速度,借鉴word2vec中的经验,使用层次softmax可以加速计算,带有层次softmax加速的fastText结构可以表示为:
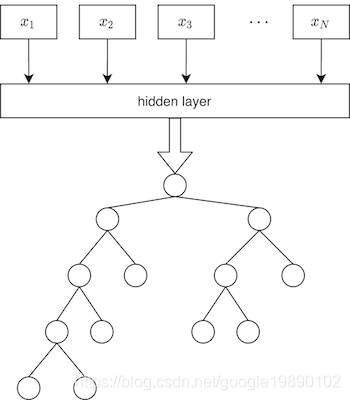
如上图,最下面是一个Huffman树,每个叶子节点代表一个类别,这样可以对每一个叶子节点编号。同时,假设一个Huffman树有个叶子节点,那么该树有个非叶子节点,将上述的Huffman树抽象出来,如下图所示:
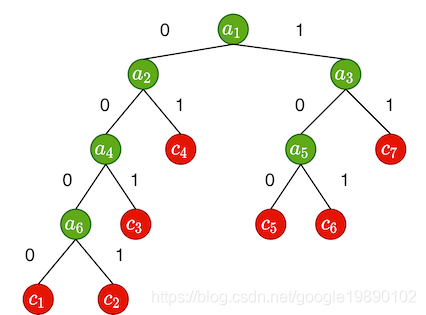
对于特征该如何计算类别,如上图中,对于每一个叶子节点,都有对应的编码,如叶子节点的编码为:0000,叶子节点的编码为:11。对于Huffman树的构建过程非本文的重点,不在本文中重复。在模型参数初始化过程中,需要同时初始化非叶子节点的向量表示,如图中的,假设对于特征,其所属的类别为,因此找到的编码和路径,我们发现需要经过的非叶子节点为:,其对应的编码为:001,因此计算过程为:
同样,每一个非叶子节点的向量也参与模型的训练。在预测过程中,直接可以计算出属于每一个叶子节点的概率。
参考文献
[1] Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759, 2016
[2] fastText