1. 概述
谷歌在2016年发表的文章《Deep Neural Networks for YouTube Recommendations》成为行业内争相跟进的技术方案,其基本的算法思想也成为深度学习在推进系统领域的成功的范例。在YouTube的推荐过程中,把推荐过程分为召回和排序两个阶段,在召回阶段,其主要目的是从百万级的视频中检索除一部分的视频用于之后的排序,对于召回阶段,需要处理的是全量的数据,由于数据量巨大,这就对召回的速度有很高的要求。
2. 算法原理
在YouTube的召回模型(有时也被称为DeepMatch,下面统称为DeepMatch)中,将视频的召回问题转化成一个多类别的分类问题,即每一个视频为一个类别,这个与word2vec的算法思路一致(每个词为一个类别)。假设是视频的集合,对于用户和上下文,在时刻,第个视频被召回的概率为:
其中,表示的是组合的向量,表示的是候选视频的向量。召回模型的模型结构与一般的MLP一致,大体结构如下图所示:
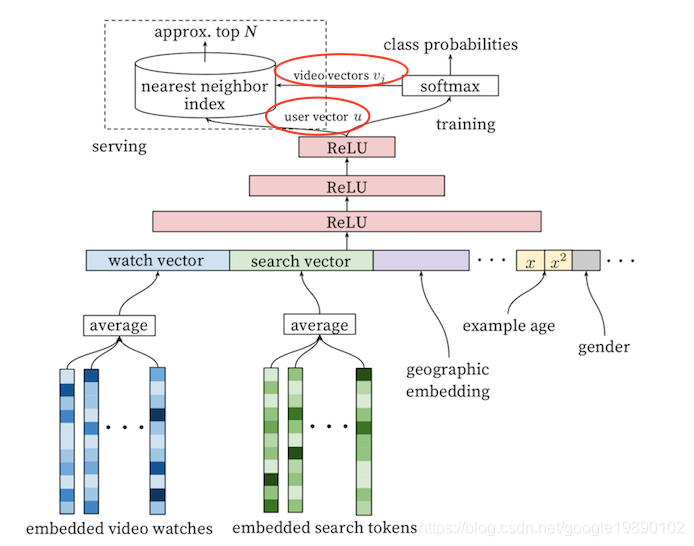
2.1. 特征选择和特征处理
为了表征,模型中的特征主要是使用用户的静态特征和隐式反馈的一些数据。从图中可以看出,模型的输入包括用户的观看过的视频的embedding,用户搜索过的token的embedding,用户的地理信息embedding,用户的年龄和性别信息,下面分别对这些特征以对应特征的处理方法做一些介绍。
- embedded video watches。这是第一部分的特征,也是较为直接的特征,即对用户观看过的视频做embedding操作,取用户观看过视频的ID,并通过embedding方式将其转换成向量,并对其做average作为watch vector。
- embedded search tokens。这部分的特征来自于用户的历史搜索,将用户的历史搜索的词转换成向量,并对其做average作为search vector。
- 人口统计信息。主要包括年龄,性别,登录状态,地理位置以及设备等,这类信息可通过归一化直接作为一维特征。
- example age。这是一类比较特殊的特征。
对于YouTube这样的平台来说,每一秒中都有大量视频被上传,推荐最新的视频对于YouTube来说是极其重要的。同时,数据也显示用户更倾向于尽管相关度不高但是是最新的视频。文中并没有指出这个特征是如何获取到的,只是交待了在线上服务阶段,该特征被设置为0或者负数。而对于训练过程中,一种猜测是训练的时间减去样本采集的时间。
2.2. 样本选择
对于样本的选择,DeepMatch模型中,正样本是用户所有完整观看过的视频,其余可以视作负样本。同时,对于每一个用户都生成了固定数量的训练样本,使得每个用户在损失函数中的地位都是相等的,防止一小部分超级活跃用户主导损失函数。
在处理测试集时,没有采用随机留一法(random holdout),而是把用户最近的一次观看行为作为测试集,主要是为了避免引入超越特征。
2.3. 模型训练
在模型的训练过程,DeepMatch采用了与word2vec类似的多分类方法,DeepMatch采用的是负样本采样(sample negative classes),以此将类别的数量减少。文中也提到了word2vec中常用的层次softmax的方法。
在模型中,对待用户的搜索历史或者观看历史这两维特征时,并没有选择时序模型,而是采用对历史记录取平均。防止模型对用户的时序过于敏感,文中举的例子是如果用户刚搜索过“tayer swift”,你就把用户主页的推荐结果大部分变成tayer swift有关的视频,这样会导致非常差的体验。
2.4. 在线服务
对于在线服务来说,除了模型的效果外,最重要的是对性能的要求,在DeepMatch中使用预先训练好的用户向量(上图中的user vector)和视频的向量(上图中的vedio vectors ),通过计算两个向量的相似度作为召回的方法,那么如何产出用户向量和视频向量?其中,用户向量取模型最后一层激活函数ReLU的输出,这一点也比较好理解,对于模型的输入要么是用户的行为日志,要么是用户的静态属性,通过神经网络,能够学到对用户的表示。而模型的目标是计算第个视频的概率,其过程可以表示为:
此时学习出的权重矩阵就是视频的向量。在线服务部分如下图所示:
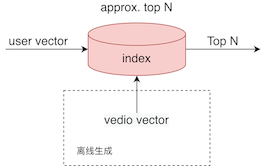
向量之间的相似度的计算目前有很多的ANN库可以支持,如Faiss。
参考文献
[1] Covington P , Adams J , Sargin E . Deep Neural Networks for YouTube Recommendations[J]. 2016:191-198.