1. 概述
随着神经网络,尤其是深度学习算法的发展,神经网络在文本分类任务中取得了很大的发展,提出了各种解决方案,如CNN在文本分类中的应用,RNN,LSTM等等,相比较于CNN以及RNN方法,LSTM可以学习长距离的语义信息。Attention-Based BiLSTM结合双向的LSTM(Bidirectional LSTM)以及Attention机制处理文本分类的相关问题,通过attention机制,该方法可以聚焦到最重要的词,从而捕获到句子中最重要的语义信息。
2. 算法思想
2.1 算法的组成部分
Attention-Based BiLSTM算法的网络结构如下所示:
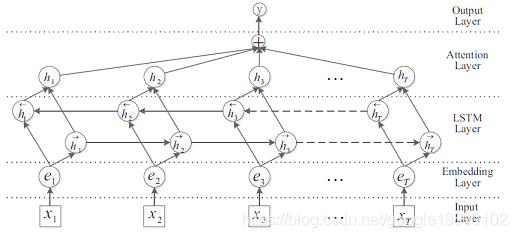
在Attention-Based BiLSTM网络中,主要由5个部分组成:
- 输入层(Input layer):指的是输入的句子,对于中文,指的是对句子分好的词;
- Embedding层:将句子中的每一个词映射成固定长度的向量;
- LSTM层:利用双向的LSTM对embedding向量计算,实际上是双向LSTM通过对词向量的计算,从而得到更高级别的句子的向量;
- Attention层:对双向LSTM的结果使用Attention加权;
- 输出层(Output layer):输出层,输出具体的结果。
注意点:
- Embedding通常有两种处理方法,一个是静态embedding,即通过事先训练好的词向量,另一种是动态embedding,即伴随着网络一起训练;
- 双向LSTM的网络结构会在其他的文章中做进一步的介绍,这里就不详细展开。
2.2. BiLSTM层的输出
假设句子通过分词算法后,得到的个词为:,每一个词经过词向量的映射得到对应的词向量,假设经过LSTM后正向的输出为,逆向的输出为,则第个词经过BiLSTM后得到的向量为:
其中,表示的是对应元素相加。
2.3. Attention机制
假设是所有个词经过BiLSTM后得到的向量的集合:,那么Attention的计算方法如下:
其中,,表示的是向量的维度,对应的,的维度为:。
其中,表示的是需要学习的参数,的维度为,的维度为。
其中,的维度为。
最终用于分类的向量表示为:。
2.4. 分类
针对句子,通过上述的BiLSTM以及Attention机制,得到了对应的表示矩阵:,其维度为。分类器以为输入:
参考文献
[1] Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification