1. 前言
随着互联网技术的发展,每一个业务都与数据息息相关,如搜索,推荐。这些业务有一个共同的特点是连接用户和数据。随着数据量的不断增加,对大数据的处理的要求也就会越来越高,在这期间出现了很多大数据的处理平台和工具,如Hadoop,Storm等。在不同的应用场景中也有不一样的数据架构,那么什么是大数据架构,引用如下的定义:
A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional database systems.
从上述的定义来说,大数据架构主要是完成数据采集,处理以及分析的数据系统,其中数据系统提供了数据存储和数据查询的功能。对于一个完备的数据系统,需要具备一些关键的特性,如:容错性和健壮性,扩展性等等。单纯利用大数据处理平台很难同时完成数据的存储和数据的查询操作,以大家熟悉的Hadoop为例,Hadoop是一个功能强大的批处理工具,但是无法在低延迟的情况下完成数据的查询工作。
Lambda架构正在在这种需求下被设计出来的一个实时大数据框架,需要注意的是,Lambda并不是一个具有实体的软件产品,而是一个指导大数据系统搭建的架构模型。Lambda架构应具备实时大数据系统所应具备的一些关键特性,如容错性,健壮性,低延迟,可扩展,通用性,方便查询等。
2. Lambda架构
2.1. Lambda架构定义
Lambda架构是由Nathan Marz在2011年提出的一个实时大数据处理框架,用于处理大数据批量离线处理和实时数据处理的需求。引用Wikipedia对Lambda架构的定义:
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods.
从定义看出,Lambda架构充分利用了批处理和实时处理两个流程。
2.2. Lambda架构
Lambda架构的整体架构图如下所示(来源参考文献1):
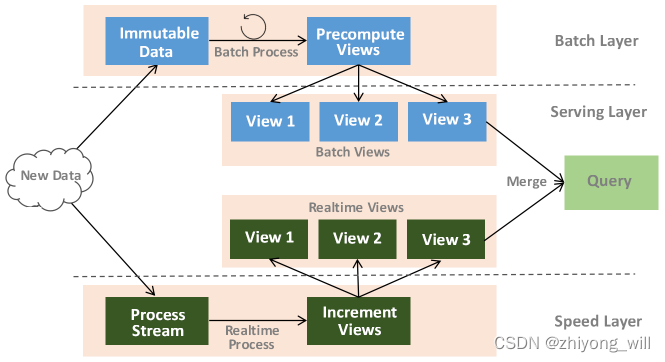
在Lambda架构中将系统架构拆分为三层,分别为:Batch Layer,Speed Layer和Serving Layer。其中,Batch Layer用于批量处理全部的数据,Speed Layer用于处理增量的数据,在Serving Layer,综合Batch Layer生成的Batch Views和Speed Layer生成的Realtime Views,提供给用户查询最终的结果。
综上所述,Lambda架构通过Batch Layer和Speed Layer的两层设计实现了在一个系统内同时支持实时和批处理的数据处理;在查询阶段,通过Serving Layer在逻辑上统一了两种数据源的接口。
2.2.1. Batch Layer
Lambda架构的目标是同时支持大数据批量离线处理和实时数据处理,在其分层的设计下,Batch Layer通过预计算对全量数据进行批处理,生成不同的Batch Views,其中,预计算的流程会根据不同的业务设置不同的时间间隔。Batch Layer层的结构图下所示:

2.2.2. Speed Layer
Speed Layer用于支撑Lambda架构的实时数据处理流程,Batch Layer每次都是处理全量的数据,由于需要处理的数据量较大,每次构建Batch Views需要花费大量时间,这就导致在构建的过程中无法感知数据的变化,Speed Layer专门用于对数据变化的监测,用来处理增量的实时数据,对数据计算生成Realtime Views。Speed Layer层的结构图下所示:

2.2.3. Serving Layer
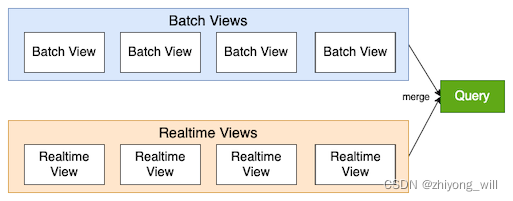
Serving Layer用于响应用户的查询请求,并将Batch Views和Realtime Views的结果进行了合并,得到最后的结果,返回给用户。具体过程如下图所示:
2.3. Lambda架构实例
由Lambda的定义可知,Lambda架构只是一个实时大数据处理框架,并不是一个大数据处理工具。在依照Lambda架构的实际设计中,可以根据实际的需求选择合适的工具或者组建,从参考文献3中总结到如下的图:
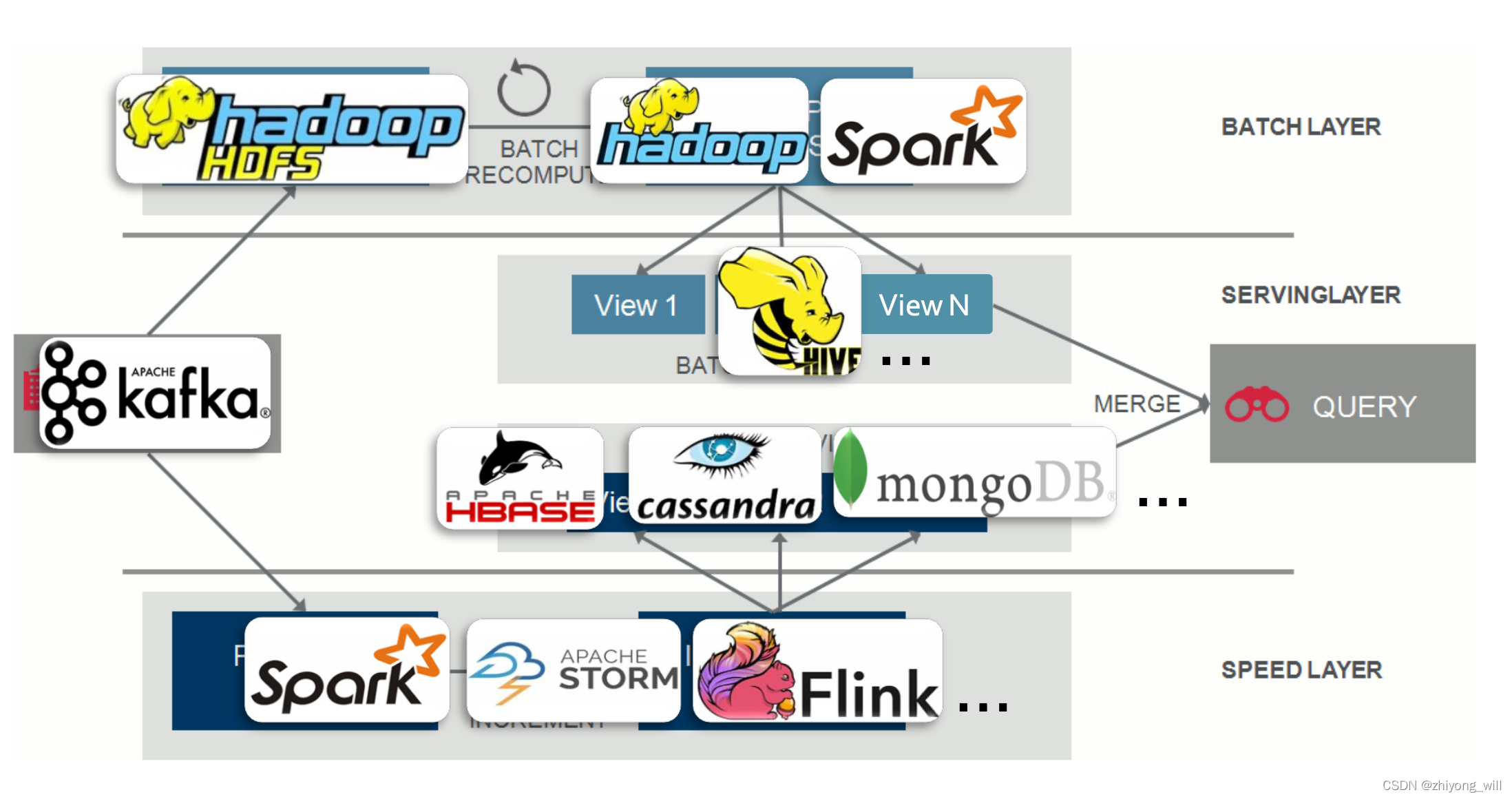
由上图可以看到,Spark Streaming/Storm/Flink可以用来构建Speed Layer,Spark/MapReduce可以用于构建Batch Layer,HBase/Redis/MongoDB可以用于存储。
3. 总结
Lambda架构是大数据中一个非常重要的架构设计,通过分层设计的思想,分别处理批量数据和增量数据,以满足实时性查询的要求。