Neural Factorization Machines(NFM)
搜索·推荐·广告 | 2022年04月05日 | 阅读:2429次
1. 概述
Neural Factorization Machines(NFM)[1]是在2017年提出的用于求解CTR问题的算法模型,在Wide & Deep模型被提出后,相继出现了一些改进的算法模型,如DeepFM和DCN可以看成是对于Wide & Deep模型中Wide部分的改进,而此处的NFM模型则是可以看作是对Deep部分的改进。从模型的名字来看,NFM包含了两个部分,第一为Neural,这部分与神经网络相关,第二为Factorization Machines,这部分与FM相关。对于FM模型,文章中提到了可以从深度学习网络结构的角度来看待,此时FM就可以看作是由单层LR和二阶特征交叉组成的Wide & Deep模型,与Google提出的Wide & Deep模型的不同之处就是Deep部分是二阶隐向量相乘。从这个角度上来看,NFM是在FM的基础上利用NN模型代替FM中的Deep部分,而这个NN与Wide & Deep中的Deep的不同是NFM中的Deep中包含了Bi-Interaction的层,用于对特征做二阶交叉运算。综上,NFM的优化点主要为:
- 在深度网络中引入Bi-Interaction做进一步的特征交叉。
- 对比FM,深度网络能够学习更高阶的非线形的特征交叉。
2. 算法原理
2.1. NFM模型的网络结构
完整的NFM的网络结构如下图所示:
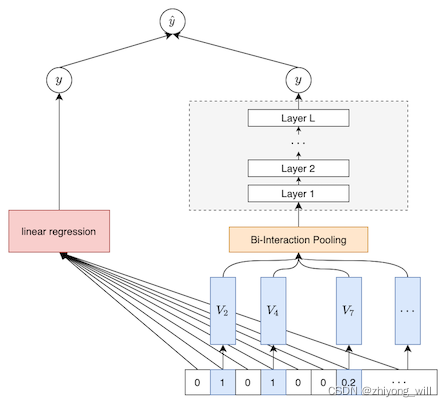
对于NFM模型,假设输入的稀疏经one-hot编码后的向量为x∈Rn,NFM模型的输出为:
y^NFM(x)=w0+i=1∑nwixi+f(x)
其中,w0+∑i=1nwixi如上图中的linear regression,f(x)为上图中的右半部分。对于FM算法,其表达式为:
y^FM(x)=w0+i=1∑nwixi+i=1∑n−1j=i+1∑n⟨vi,vj⟩xixj
从两者的数学表达式可以看出,FM模型是NFM的特殊形式,即满足:f(x)=∑i=1n−1∑j=i+1n⟨vi,vj⟩xixj。我们发现如何构造f(x)式NFM模型中的关键部分。
2.2. NFM模型中的特征交叉
NFM模型中的特征交叉f(x)的结构如下图所示:
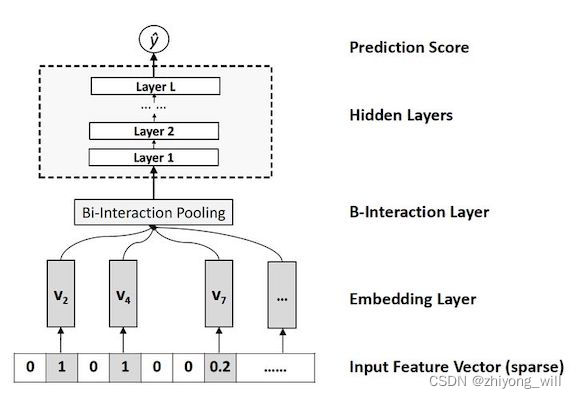
如上图,NFM中特征交叉部分f(x)是一个深度神经网络模型,在特征交叉部分f(x)的网络中,主要包括Embedding层,Bi-Interaction层,隐含层以及预测层。
2.2.1. Embedding层
Embedding层的作用是将稀疏的one-hot特征转换成稠密的向量表示,这个操作是深度神经网络的必备操作方法。假设转换后的embeding向量为:
Vx={x1v1,⋯,xnvn}
2.2.2. Bi-Interaction层
对稀疏特征处理后就可以进入到深度学习模型的计算中,在NFM中,首先进入到Bi-Interaction层中,Bi-Interaction Pooling的主要作用是对Embedding后的特征学习特征交叉,其具体格式为:
fBI(Vx)=i=1∑n−1j=i+1∑nxivi⊙xjvj
其中,⊙表示的是两个向量的元素乘积,即(vi⊙vj)k=vikvjk。可以看到Bi-Interaction的输出为两个向量的交叉。
2.2.3. Hidden层
在Bi-Interaction层之上是堆叠了一系列的隐含层,主要的目的是学习更高阶的特征交叉,用数学的表述为:
z1=σ1(W1fBI(Vx)+b1)z2=σ2(W2z1+b2)⋯⋯zL=σL(WLzL−1+bL)
其中,L表示的是隐含层的层数,WL,bL和σL分别为第L的网络权重,偏置和激活函数。
2.2.4. Prediction层
经过多个隐含层后,得到隐含层的输出zL,最终将隐含层的输出送入到预测层中,得到Deep侧的输出结果,即为:
f(x)=hTzL
其中,h为输出层的权重,最终NFM模型的输出结果为:
y^NFM(x)=w0+i=1∑nwixi+hTσL(WL(⋯σ1(W1fBI(Vx)+b1)⋯)+bL)
其中,Θ={w0,{wi,vi},h,{Wl,bl}}为模型的参数。
3. 总结
通过上述的拆分会发现NFM与FM以及Wide & Deep模型之间有着很大的相似性,不同在于NFM中不光包含了FM中的二阶特征,同时利用DNN的特性构造更高阶非线性的交叉,总体而言,主要还是集中在特征交叉的工作上。
参考文献
[1] He X , Chua T S . Neural Factorization Machines for Sparse Predictive Analytics[J]. ACM SIGIR FORUM, 2017, 51(cd):355-364.