1. 概述
Seq2Seq是Sequence to Sequence的缩写,作用是将一个序列(sequence)映射成另一个序列(sequence)。文献[1]和文献[2]分别提出利用深度神经网络DNN实现端到端的Seq2Seq学习,将Seq2Seq应用于神经机器翻译(Neural Machine Translation,NMT),唯一不同的是在[1]中使用LSTM作为基础网络,而在[2]中则是使用的是RNN。在Seq2Seq框架中包含了两个模块,一个是encoder模块,另一个是decoder模块。这种同时包含encoder和decoder的结构与AutoEncoder网络相似,不同的是AutoEncoder模型是将输入通过encoder的网络生成中间的结果,并通过decoder对中间的结果还原,AutoEncoder的模型结构如下图所示:

而在Seq2Seq中,相同的是两者都包含了Encoder和Decoder,不同的是,在Seq2Seq中,输入与输出并不是相同的,而在AutoEncoder中,输入与输出是相同的。
2. Seq2Seq框架
2.1. Seq2Seq框架的概述
Seq2Seq框架最初是在神经机器翻译(Neural Machine Translation,NMT)领域中提出,用于将一种语言(sequence)翻译成另一种语言(sequence)。由于在Seq2Seq结构中同时包含了encoder和decoder的结构,通常Seq2Seq又被称为Encoder-Decoder结构,Seq2Seq的结构如下图所示:
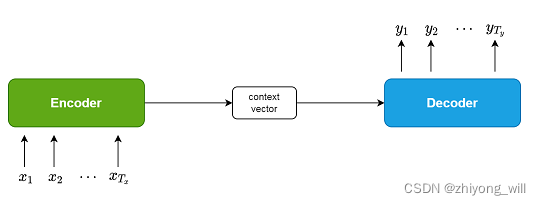
在Seq2Seq结构中,Encoder和Decoder分别是两个独立的神经网络模型,用于对不同的文本建模,通常对序列化文本建模的方法如LSTM[1],RNN[2]等。Encoder通过神经网络将原始的输入转换成固定长度的中间向量,Decoder将此中间向量作为输入,得到最终的输出。
对于机器翻译NMT问题,从概率的角度分析,即对于给定输入,求目标输出,使得条件概率最大,即。
2.1. Encoder
为了便于阐述,这里选取RNN[2](Recurrent Neural Network)作为Encoder和Decoder,一个典型的RNN结构如下图所示:

在RNN中,当前时刻的隐含层状态是由上一时刻的隐含层状态和当前时刻的输入共同决定的,可由下式表示:
假设在Seq2Seq框架中,输入序列为,其中,,输出序列为,其中,。在编码阶段,RNN通过学习到每个时刻的隐含层状态后,最终得到所有隐含层状态序列:
具体过程可由下图表示:
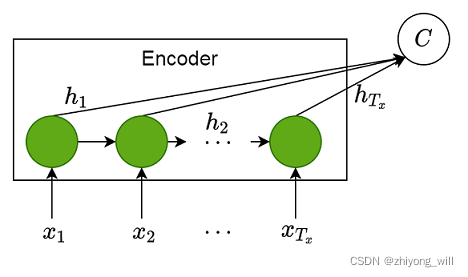
通过对这些隐藏层的状态进行汇总,得到上图中固定长度的语义编码向量,如下式所示:
其中表示某种映射函数。通常取最后的隐含层状态作为语义编码向量,即
2.2. Decoder
在解码阶段,在当前时刻,根据在编码阶段得到的语义向量和已经生成的输出序列来预测当前的输出的,其具体过程可由下图表示:
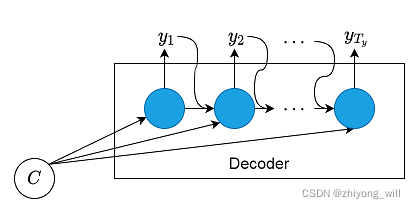
上述过程可以由下式表示:
简化可得:
其中表示某种映射函数。在RNN中,上式可简化为:
其中表示时刻的输出,表示Decoder中RNN在时刻的神经元的隐含层的状态, 代表的是Encoder网络生成的语义向量。
3. Attention
上述的基于Encoder-Decoder的Seq2Seq框架成功应用在NMT任务中,但是在Encoder和Decoder之间的固定长度的语义向量限制了Seq2Seq框架的性能。主要表现为固定长度的语义向量可能无法完整表示整个序列的信息,尤其是对于较长的句子。为了解决长句子表示的问题,Bahdanau等人[3]在2016年在Seq2Seq框架中引入了Attention机制,同时将上述的Encoder阶段中的RNN替换成双向的RNN(BiRNN),即bidirectional recurrent neural network。
3.1. 带有Attention机制的Encoder
在[3]中的Encoder中,采用的是BiRNN,具体过程如下图所示:
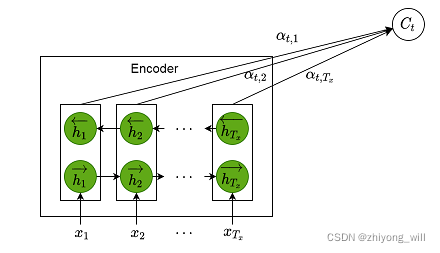
对于BiRNN,其包含了两个阶段的RNN过程,分别为正向RNN和反向RNN,其中,正向RNN生成的隐含层状态序列为:
反向RNN生成的隐含层状态序列为:
对于时刻的隐含层状态通常是将正向和反向的隐含层状态concat在一起,即:
3.2. 带有Attention机制的Decoder
与上述的Decoder一致,这里的Decoder也是一个标准的RNN,其过程可由下式表示:
注意到此处与上面不一样的是这里的Encoder网络生成的语义向量不再是固定的,而是变化的。对于第个词的Decoder过程中,为:
其中,为归一化权重,其具体为:
其中,表示的是第个输出前一个隐藏层状态与第个输入隐层向量之间的相关性,可以通过一个MLP神经网络进行计算,即:
其具体过程可由下图表示:
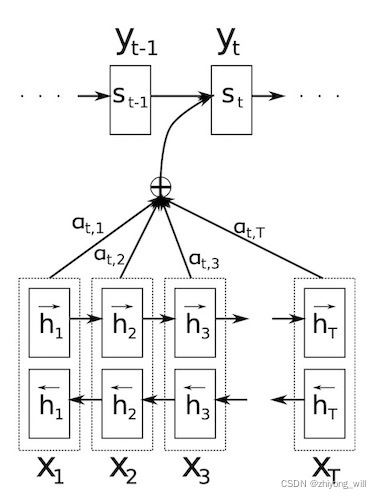
这里的Attention机制对所有的编码器隐含层状态都分配了权重,表示的是输出与编码器中每个隐含层状态的相关关系。
4. 总结
与原始的Encoder-Decoder模型相比,加入Attention机制后最大的区别就是原始的Encoder将所有输入信息都编码进一个固定长度的向量之中。而加入Attention后,Encoder将输入编码成一个向量的序列,在Decoder的时候,每一步都会选择性的从向量序列中挑选一个集合进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。
参考文献
[1] Cho K, Merrienboer B V, Gulcehre C, et al. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation[J]. Computer Science, 2014.
[2] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
[3] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
[4] 深度学习中的注意力机制