1. 概述
诸如BERT等预训练模型的提出显著的提升了自然语言处理任务的效果,但是随着模型的越来越复杂,同样带来了很多的问题,如参数过多,模型过大,推理事件过长,计算资源需求大等。近年来,通过模型压缩的方式来减小模型的大小也是一个重要的研究方向,其中,知识蒸馏也是常用的一种模型压缩方法。TinyBERT[1]是一种针对transformer-based模型的知识蒸馏方法,以BERT为Teacher模型蒸馏得到一个较小的模型TinyBERT。四层结构的TinyBERT在GLUE benchmark上可以达到BERT的96.8%及以上的性能表现,同时模型缩小7.5倍,推理速度提升9.4倍。六层结构的TinyBERT可以达到和BERT同样的性能表现。
2. 算法原理
为了能够将原始的BERT模型蒸馏到TinyBERT,因此,在[1]中提出了一种新的针对Transformer网络特殊设计的蒸馏方法,同时,因为BERT模型的训练分成了两个部分,分别为预训练和针对特定任务的Fine-tuning,因此在TinyBERT模型的蒸馏训练过程中也设计了两阶段的学习框架,在预训练和Fine-tuning阶段都进行蒸馏,以确保TinyBERT模型能够从BERT模型中学习到一般的语义知识和特定任务知识。
2.1. 知识蒸馏
知识蒸馏(knowledge distillation)[2]是模型压缩的一种常用的方法,对于一个完整的知识蒸馏过程,有两个模型,分别为Teacher模型和Student模型,通过学习将已经训练好的Teacher模型中的知识迁移到小的Student模型中。其具体过程如下图所示:
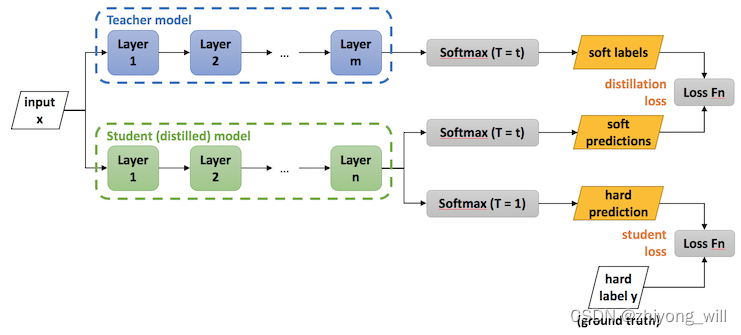
对于Student模型,其目标函数有两个,分别为蒸馏的loss(distillation loss)和自身的loss(student loss),Student模型最终的损失函数为:
其中,表示的是蒸馏的loss,表示的是自身的loss。
2.2. Transformer Distillation
BERT模型是由多个Transformer模块(Self-Attention+FFN)组成,单个Self-Attention+FFN模块如下图所示:
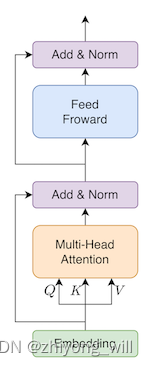
假设BERT模型中有层的Transformer Layer,在蒸馏的过程中,BERT模型作为Teacher模型,而需要蒸馏的模型TinyBERT模型作为Student模型,其Transformer Layer的层数假设为,则有,此时需要找到一个对应关系:,表示的是在Student模型中的第层对应于Teacher模型中的第层,即层。TinyBERT的Embedding层和预测层也是从BERT的相应层学习知识的,其中Embedding层对应的层数为,预测层对应的层数为,对应到BERT中的层数分别为 和 。在形式上,学生模型可以通过最小化以下的目标函数来获取教师模型的知识:
其中,是给定的模型层的损失函数,表示的是由第层得到的结果,表示第层蒸馏的重要程度。在TinyBERT的蒸馏过程中,又可以分为以下三个部分:
- transformer-layer distillation
- embedding-layer distillation
- prediction-layer distillation。
2.2.1. Transformer-layer Distillation
Transformer-layer的蒸馏由Attention Based蒸馏和Hidden States Based蒸馏两部分组成,具体如下图所示:
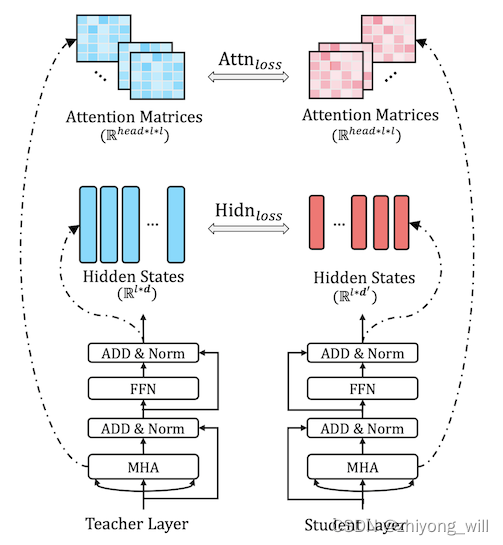
其中,在BERT中多头注意力层能够捕获到丰富的语义信息,因此,在蒸馏到TinyBERT中,提出了Attention Based蒸馏,其目的是希望使得蒸馏后的Student模型能够从Teacher模型中学习到这些语义上的信息。具体到模型中,就是让TinyBERT网络学习拟合BERT网络中的多头注意力矩阵,目标函数定义如下:
其中,代表注意力头数,代表Student或者Teacher模型中的第个注意力头对应的注意力矩阵,代表输入文本的长度。在[1]中使用注意力矩阵而不是是因为实验结果显示这样可以得到更快的收敛速度和更好的性能表现。
Hidden States Based的蒸馏是对Transformer层进行了知识蒸馏处理,目标函数定义为:
其中,矩阵和分别代表Student网络和Teacher网络的隐状态,且都是FFN的输出。和代表Teacher网络和Student网络的隐藏状态大小,且,因为Student网络总是小于Teacher网络。是一个参数矩阵,将Student网络的隐藏状态投影到Teacher网络隐藏状态所在的空间。
2.2.2. Embedding-layer Distillation
Embedding层的蒸馏与Hidden States Based蒸馏一致,其目标函数为:
其中 ,分别代表Student网络和Teacher网络的Embedding,的作用与的作用一致。
2.2.3. Prediction-layer Distillation
除了对中间层做蒸馏,同样对于最终的预测层也要进行蒸馏,其目标函数为:
其中,,分别是Student网络和Teacher网络预测的logits向量,表示的是交叉熵损失,是温度值,在实验中得知,当时效果最好。
综合上述三个部分的Loss函数,则可以得到Teacher网络和Student网络之间对应层的蒸馏损失如下:
2.3. 两阶段的训练
对于BERT的训练来说分为两个阶段,分别为预训练和fine-tunning,预训练阶段可以使得BERT模型能够学习到更强的语义信息,fine-tunning阶段是为了使模型更适配具体的任务。因此在蒸馏的过程中也需要针对两个阶段都蒸馏,即general distillation和task-specific distillation,具体如下图所示:

在general distillation阶段,通过蒸馏使得TinyBERT能够学习到BERT中的语义知识,能够提升TinyBERT的泛化能力,而task-specific distillation可以进一步获取到fine-tuned BERT中的知识。
3. 总结
在TinyBERT中,精简了BERT模型的大小,设计了三种层的蒸馏,分别为transformer-layer,embedding-layer以及prediction-layer。同时,为了能够对以上三层的蒸馏,文中设计了两阶段的训练过程,分别与BERT的训练过程对应,即预训练和fine-tunning。
参考文献
[1] Jiao X, Yin Y, Shang L, et al. Tinybert: Distilling bert for natural language understanding[J]. arXiv preprint arXiv:1909.10351, 2019.
[2] 知识蒸馏基本原理