1. 概述
一般在对CVR建模的过程中,正样本选择的是在点击后有转化的样本作为正样本,负样本则是在点击后没有转化的样本作为负样本。然而,这样的建模方式存在一定的问题:
- Sample Selection Bias(SSB)问题,即样本选择有偏。在training和inference阶段面对的样本空间不一致,在training阶段,选择的样本都是点击后的样本,而在inference阶段,面对的是所有的可能曝光的样本;
- Data Sparsity (DS)问题,即样本稀疏。点击的样本只是占了曝光样本的很小的一部分,如下图所示:

为了解决以上的这些问题,阿里在2018年提出了ESMM(Entire space multi-task model)[1]模型,从名称来看,CVR的建模也是在全空间上的,同时这是一个基于多任务建模的模型。
2. 算法原理
2.1. CVR建模
一条样本的整个过程包括了“曝光->点击->转化”,这是一个顺序的过程。假设表示的是一条曝光样本,表示的是该曝光样本是否被点击,表示的是该样本在曝光点击后是否有转化,对CVR建模是预估转化率:,与之相关的两个概率是点击率(CTR):和点击转化率(CTCVR):,这三者之间的关系为:
因此,在单独对CVR建模的过程中,需要选择的样本空间是在所有点击样本中,即上述过程的“点击->转化”阶段,如果存在转化,则在CVR中为正样本,否则为负样本。反观CTR建模的过程,选择的样本空间在上述过程的“曝光->点击”阶段。
而在inference阶段,所需面对的样本是所有可能曝光的样本。基于以上的公式,对于CTCVR的建模,选择的样本空间则是上述过程的融合,即“曝光->转化”。对上述公式进行简单的变换,得到如下的公式:
这样就能直接利用“曝光”样本空间中的样本直接对CVR建模,不过在对CVR建模的过程中需要同时对CTR以及CTCVR建模。
2.2. ESMM模型结构
基于以上的分析,在ESMM模型的建模过程中引入两个辅助任务,即:CTR建模和CTCVR建模,ESMM的网络结构如下图所示:
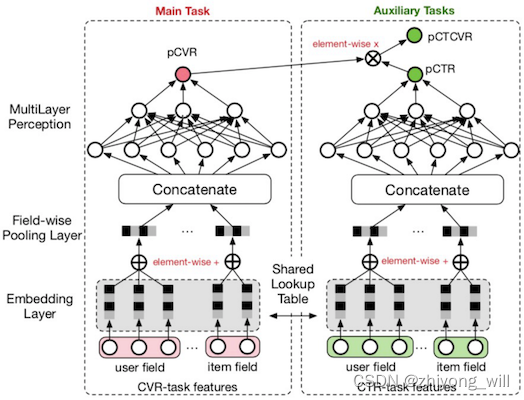
在ESMM模型结构中,有两个特点:
第一,在ESMM结构中包含了两个塔,如上图所示,左侧是一个CVR任务的塔,右侧是一个CTR任务的塔,两个塔可以构建两个任务,分别为pCTR和pCTCVR,这样样本分别是从“曝光->点击”和“曝光->转化”,解决了样本空间的问题,通过模型中参数的学习,可以把CVR塔中的参数学习到,这样对于CVR塔的样本空间即为“曝光->转化”。
第二,在两个塔的底层Embedding层是参数共享的,这样能充分利用CTR任务重的样本,缓解传统的CVR建模过程中面临的数据稀疏问题。
2.3. 损失函数
因为在ESMM中存在两个学习任务,分别为CTR和CTCVR,则最终的损失函数为:
其中,表示的是CVR塔中的参数,表示的是CTR塔中的参数,表示的是样本在CTR任务上的label,表示的是样本在CVR任务上的label,表示的样本在CTR塔中的结果,表示的是样本在CVR塔中的结果。
2.4. 代码结构
在参考[2]中有具体的ESMM的实现,以该代码为例,ESMM结构的代码如下:
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list) # 特征处理
# DNN函数针对的上述的MLP网络结构
ctr_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(
dnn_input)
cvr_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(
dnn_input)
# 由MLP最后一层到最后的输出
ctr_logit = Dense(1, use_bias=False)(ctr_output)
cvr_logit = Dense(1, use_bias=False)(cvr_output)
# 计算最终的sigmoid结果
ctr_pred = PredictionLayer('binary', name=task_names[0])(ctr_logit)
cvr_pred = PredictionLayer('binary')(cvr_logit)
# 计算ctcvr的值
ctcvr_pred = Multiply(name=task_names[1])([ctr_pred, cvr_pred]) # CTCVR = CTR * CVR
model = Model(inputs=inputs_list, outputs=[ctr_pred, ctcvr_pred])
3. 总结
在ESMM网络中,通过引入两个辅助任务CTR和CTCVR,由于这两个任务的输入空间都变成了“曝光”,从而解决了传统CVR建模中在training和inference两个过程中输入空间不一致的问题,另一个方面,因为“曝光->点击”阶段的样本量要比“点击->转化”阶段的样本量要大,鉴于Embedding层参数的共享,因此,能够充分学习到Embedding层的参数。
参考文献
[1] Ma X, Zhao L, Huang G, et al. Entire space multi-task model: An effective approach for estimating post-click conversion rate[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018: 1137-1140.
[2] DeepCTR