1. 概述
Transformer[1]是Google在2017年提出的一种Seq2Seq结构的语言模型,在Transformer中首次使用Self-Atttention机制完全代替了基于RNN的模型结构,使得模型可以并行化训练,同时解决了在基于RNN模型中出现了长距离依赖问题,因为在Self-Attention中能够对全局的信息建模。
Transformer结构是一个标准的Seq2Seq结构,包含了Encoder和Decoder两个部分。其中基于Encoder的Bert[2]模型和基于Decoder的GPT[3]模型刷新了NLP中多个任务的记录,在NLP多种应用中取得了巨大的成功。以BERT模型为例,在BERT模型中,首先在大规模数据上利用无监督学习训练语言模型,对于具体的下游任务,如文本分类,利用预训练模型在下游数据上Fine-tuning。
基于Transformer框架的模型在NLP领域大获成功,而在CV领域还是基于CNN模型的情况下,能否将Transformer引入到CV中呢?ViT(Vision Transformer)[4]作为一种尝试,希望能够通过尽可能少的模型改动,实现Transformer在CV中的应用。
2. 算法原理
2.1. Transformer的基本原理
Transformer框架是一个典型的Seq2Seq结构,包括了Encoder和Decoder两个部分,其框架结构如下图所示:

在Transformer框架结构中,Encoder部分如上图的左半部分,Decoder部分如上图的右半部分。由于在ViT中是以Encoder部分为主要部分,同时,BERT模型也是以Transformer中Encoder为原型的模型,因此在这里对Bert模型做简单介绍,对于完整的Transformer框架的介绍可见参考文献[5]。BERT是基于上下文的预训练模型,BERT模型的训练分为两步:第一,pre-training;第二,fine-tuning。其中,在pre-training阶段,首先会通过大量的文本对BERT模型进行预训练,然而,标注样本是非常珍贵的,在BERT中则是选用大量的未标注样本来预训练BERT模型。在fine-tuning阶段,会针对不同的下游任务适当改造模型结构,同时,通过具体任务的样本,重新调整模型中的参数。
2.1.1. BERT模型的网络结构
BERT模型是Transformer结构的Encoder部分,其基本的网络结构如下图所示:
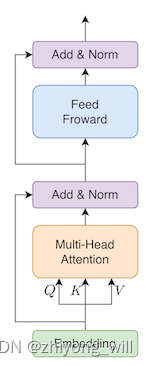
这个结构与Transformer中的Encoder结构是完全一致的。
2.1.2. BERT模型的输入Embedding
为了使得BERT能够适配更多的应用,模型在pre-training阶段,使用了Masked Language Model(MLM)和Next Sentence Prediction(NSP)两种任务作为模型预训练的任务,其中MLM可以学习到词的Embedding,NSP可以学习到句子的Embedding。在Transformer中,输入中会将词向量与位置向量相加,而在BERT中,为了能适配上述的两个任务,即MLM和NSP,这里的Embedding包含了三种Embedding的和,如下图所示:
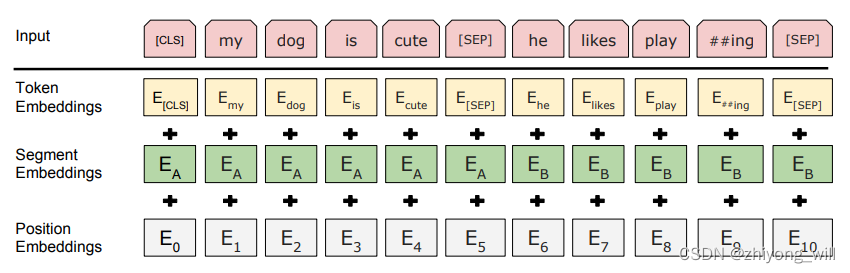
其中,Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任,Segment Embeddings用来区别两种句子,这是在预训练阶段,针对NSP任务的输入,Position Embeddings是位置向量,但是和Transformer中不一样,与词向量一样,是通过学习出来的。此处包含了两种标记,一个是[CLS],可以理解为整个输入特征的向量表示;另一个是[SEP],用于区分不同的句子。
2.1.3. 重要的Multi-Head Attention
Multi-Head Attention结构是所以基于Transformer框架模型的灵魂,Multi-Head Attention结构是由多个Scaled Dot-Product Attention模块组合而成,如下图所示:
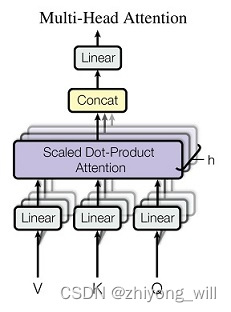
其过程可以表示为:
其中,每一个就是一个Scaled Dot-Product Attention。Multi-head Attention相当于多个不同的Scaled Dot-Product Attention的集成,引入Multi-head Attention可以扩大模型的表征能力,同时这里面的个Scaled Dot-Product Attention模块是可以并行的,没有层与层之间的依赖,相比于RNN,可以提升效率。而Scaled Dot-Product Attention的计算方法为:
其中最主要的目的是对点积缩放。计算过程可由下图表示:

2.1.4. 下游任务的fine-tuning
在预训练阶段,BERT采用了Masked Language Model和Next Sentence Prediction两个训练任务作为其语言模型的训练,其中,Masked Language Model的原理是随机将一些词替换成[MASK],在训练的过程中,通过上下文信息来预测被mask的词;Next Sentence Prediction的目的是让模型理解两个橘子之间的关系,训练的输入是两个句子,BERT模型需要判断后一个句子是不是前一个句子的下一句。这两个任务最大的特点就是可以无监督学习,这样就可以避免模型对大规模标注数据依赖的问题。
在预训练模型完成后,就可以在具体的下游任务中应用BERT模型。这里以文本分类为例,句子对的分类任务,即输入是两个句子,输入如下图所示:
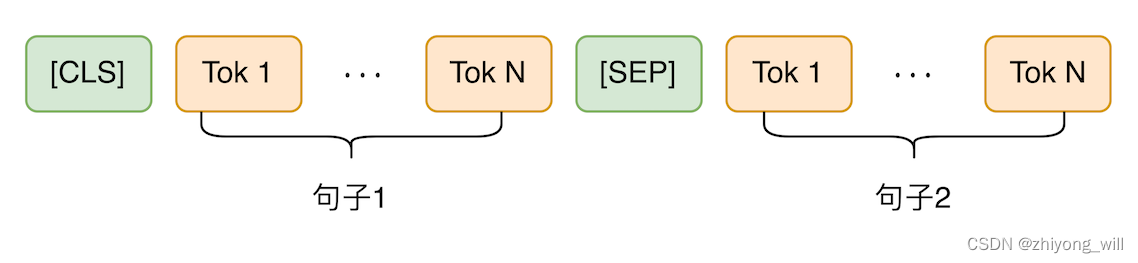
输出是BERT的第一个[CLS]的隐含层向量,在Fine-Tune阶段,加上一个权重矩阵,其中,为分类的类别数。最终通过Softmax函数得到最终的输出概率。
2.2. ViT的基本原理
ViT模型是希望能够尽可能少对Transformer模型修改,并将Transformer应用于图像分类任务的模型。ViT模型也是基于Transformer的Encoder部分,这一点与BERT较为相似,同时对Encoder部分尽可能少的修改。
2.2.1. ViT的网络结构
ViT的网络结构如下图所示:
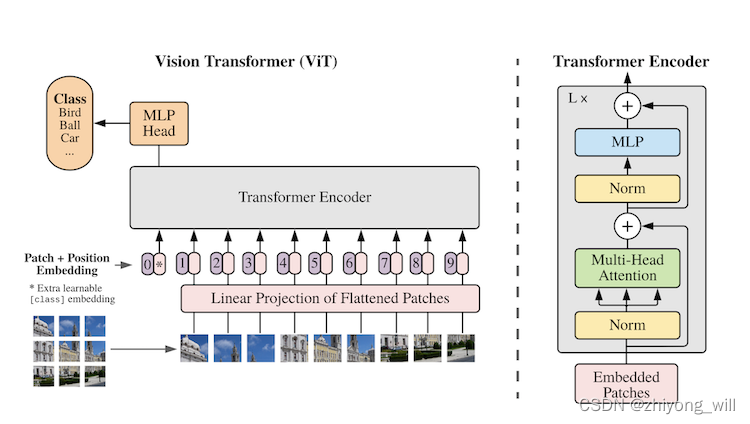
ViT模型的网络结构如上图的右半部分所示,与原始的Transformer中的Encoder不同的是Norm所在的位置不同,类似BERT模型中[class]标记位的设置,ViT在Transformer输入序列前增加了一个额外可学习的[class]标记位,并且该位置的Transformer Encoder输出作为图像特征。
Vision Transformer(ViT)将输入图片拆分成个patches,每个patch做一次线性变换降维同时嵌入位置信息,然后送入Transformer。类似BERT[CLS]标记位的设计,在ViT中,在输入序列前增加了一个额外可学习的[class]标记位,并将其最终的输出作为图像特征,最后利用MLP做最后的分类,如上图中的左半部分所示,其中,[class]标记位为上图中Transformer Encoder的0*。那么现在的问题就是两个部分,第一,如何将图像转换成一维的序列数据,因为BERT处理的文本数据是一维的序列数据;第二,如何增加位置信息,因为在Transformer中是需要对位置信息编码的,在BERT中是通过学习出来,而在Transformer中是利用sin和cos这两个公式生成出来。
2.2.2. 图像到一维序列数据的转换
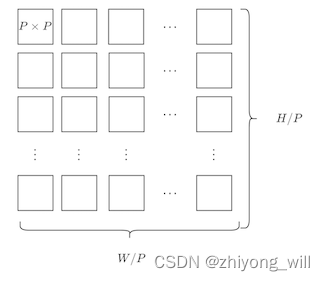
对于的图像,首先需要将其变成的2D的patch的序列,这里面,表示的是原图的分辨率,表示的通道(channel)的数目,表示的是每个patch的分辨率,表示的是patch的个数,对于一个通道,上述的这个过程可以如下图所示:
假设输入图片大小是,每个patch的大小为,则最后的总的patch个数为64。对于每个patch,我们还需要将其转换成embeding的表示,ViT中使用到了线性变换,即:
其中,,。首先对于第个patch,我们看到是将patch转换成维的向量,具体过程如下:
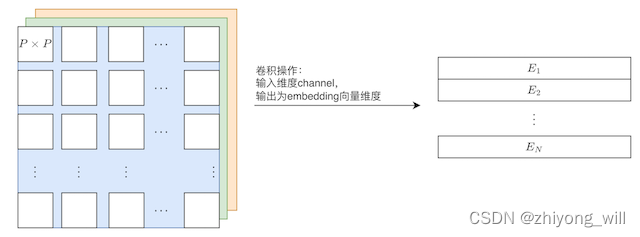
这里的卷积操作中卷积核大小为,步长为。参考文献[6]给出了较为容易理解的代码,注释的代码如下:
class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):
super().__init__()
img_size = (img_size, img_size) # 图片原始大小
patch_size = (patch_size, patch_size) # 每个patch的大小
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1]) # 拆分成每个patch后,每个维度的patch个数
self.num_patches = self.grid_size[0] * self.grid_size[1] # 总共的patch个数
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) # 对每个patch做线性变换
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() # 归一化
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = self.proj(x).flatten(2).transpose(1, 2) # 这里C即为向量的维度,HW表示的是patch的个数
x = self.norm(x)
return x
除此之外还有两个向量,分别为和。表示的给到一个用于最后图像表示的向量,用于最后的分类任务,表示的是位置向量,这两个向量都是通过随机初始化的,并在训练过程中得到的,在参考文献[6]中的代码如下:
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
通过以上的过程后,便可以直接使用标准的BERT流程开始训练,这部分不再赘述,可参见参考文献[5]和参考文献[6]的具体实现。
2.2.3. 训练目标以及fine-tune
ViT的训练与BERT是不一样的,在BERT中采用的无监督的训练,而在ViT中使用的是监督训练,使用的数据集是有标签的分类数据集,如ILSVRC-2012 ImageNet数据集,该数据集是一个包含了1000个类别的带标签的数据集。[class]标记的向量最初为,在训练过程中,通过Transformer Encoder得到[class]标记的最终向量为,对其进行归一化并以此作为图像的表示:
在训练过程中,后接一个带一个隐含层的MLP,得到整个网络的结构。在Fine-tuning时,去掉最终的这部分,直接用一个线性曾代替这部分重新训练。
在参考文献[4]中,作者设计了不同大小的网络结构,如下图所示:
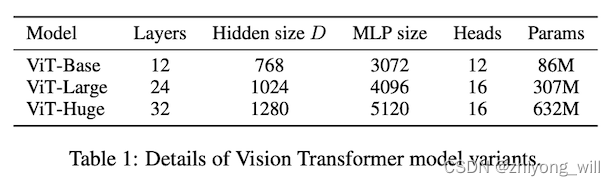
从最终的效果上来看,ViT模型的效果还是要优于传统的基于CNN的模型的:

2.2.4. 一个有意思的点
在上述的ViT的过程中,位置的向量是随机初始化的,那么最终训练出来的这个向量的值能表示其在原始图像中的真实位置吗?在参考文献[4]中设计了这样一个方法,假设有个patch,每个patch的位置向量与其他patch的位置向量计算相似度,得到了如下的一张图,其中自身的相似度为。
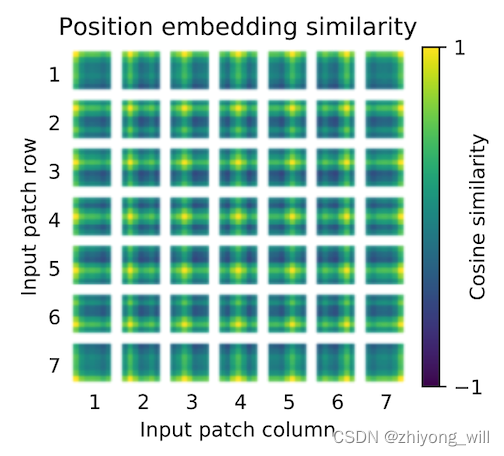
我们发现最终训练出来的位置向量已经具有了空间了信息,即与同行同列之间具有相对较高的相似度。
3. 总结
ViT模型将Transformer引入到图像的分类中,更准确的说是Transformer中的Encoder模块。为了能够尽可能少地对原始模型的修改,在ViT中将图像转换成一维的序列表示,以改成标准的文本形式,通过这种方式实现Transformer在CV中的应用。
参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[2] Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.
[3] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[4] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[5] Transformer的基本原理