1. 概述
对于一个搜索或者推荐系统来说,分阶段的设计都是当下的一个标配,主要是为了平衡效率和效果,在百度的广告系统中,也是分成了如下的三层结构:

最上层的Matching阶段负责从全库中找到与query相关的候选集,接下来的两个阶段则是根据不同的指标对候选集进行筛选,通常称中间的筛选过程为粗排,最下面的筛选过程为精排。
这种分层的方式虽然带来了性能上的保证,但同时也带来了诸如一致性的问题。一致性,简单来讲就是在召回阶段的目标是相关性,但是在排序阶段的目标是效率指标,如CPM等。这就会导致高相关的召回item由于其CPM预估分并不高,导致了在最终未能被展出。
上述也在提醒我们,尤其是做召回的同学,扩召回有可能并不会带来业务指标的提升,这在很大程度上是因为指标的不一致导致。
那么,能不能在召回阶段,综合考虑相关性和CPM,其实这就是一个多目标的问题,这样就能保证前后的一致性。在百度的Mobius[1]系统中就是要解决这样的一个问题,同时,Mobius的目标是要将召回和排序合并成一个大模型。
2. Mobius系统
2.1. 双塔召回
在Mobius系统中也是采用的双塔的召回模型,一个典型的双塔模型[2]如下所示:
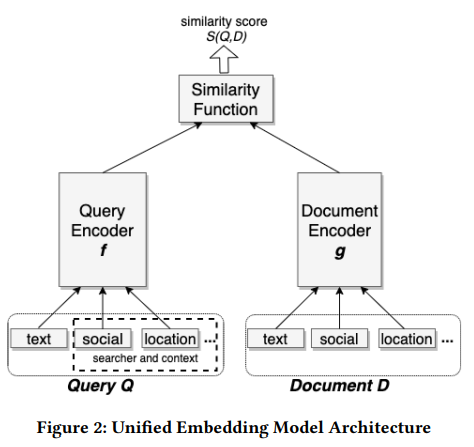
双塔召回模型的左侧塔是一个query侧的塔,也可以加上user侧的特征,做成user & query侧的塔,右侧塔是一个item侧的塔。在双塔召回模型一般需要解决的一个最重要的问题是样本空间的问题,即召回模型需要处理的是全量数据,在组织样本的时候就需要考虑训练样本的分布与预测时的数据分布是否一致。
双塔召回在分层的系统中存在着以下的一些优势:
- 能够独立生成query向量和item向量,这样在检索过程中便可以直接利用ANN的方法实现query向量和item向量的计算;
- 基于模型的方法,能够方便增加side-information。
2.2. Mobius模型结构
Mobius模型结构也是一个双塔的模型结构,具体结构如下所示:
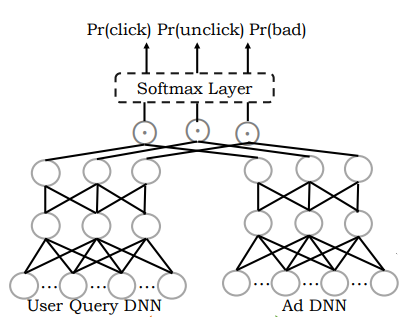
左侧的塔是user & query侧的塔,右侧的塔是ad侧的塔。与上述的双塔结构不同的是,在Mobius的目标中,包括了三个指标,分别为click,unclick和bad的概率。
2.2.1. 样本构造
对于召回模型来说,最困难的是如何组织训练样本。首先,对于数据的来源,通常选择线上的真实点击日志作为训练数据的来源。对于上述的双塔结构,其有三个目标,分别为click,unclick以及bad,需要双塔模型计算三个目标的概率。抛开bad来说,这就是典型的CTR模型,我们知道在CTR模型中的样本分别为:
- 正样本:点击的样本;
- 负样本:曝光未点击的样本;
那么此时需要增加bad情况下的样本,那么此处的bad是如何定义的呢?bad定义为:低相关性但高CTR的case。
Why?为什么是这么定义bad呢,其实可以这么理解:对于我们即将要训练的找回模型,其实我们最终的目标是希望训练好的模型能够针对特定的query和user挑选出“满足相关性要求且CTR高的ad”。但是直接利用上述的CTR的正负样本来训练CTR模型,最终将模型应用于召回模块,会存在严重的样本空间选择的问题。引入的一类case便是高CTR但是低相关性,我们需要对这部分样本建模。
因此,bad部分的样本选择为:高CTR低相关性。同时,在样本的构造过程中,有以下的一些策略:
- 为了缓解样本选择的问题,在这里选择使用数据增强(data augmentation)的方法;
- 通过相关性的计算模块得到低相关性的样本;
- 采样得到bad部分的样本。
具体的算法逻辑如下图所示:

2.2.2. 数据增强
由于利用曝光样本直接训练召回模型会存在样本选择的问题,因此需要从全库中抽取样本来作为训练样本,在传统的双塔中一般可采用:
- 点击样本作为正样本,负样本根据频率在全库采样;
- 点击样本作为正样本,负样本batch内采样。
那么此处的数据增强则更像是两者的结合,通过对曝光样本中的query和ad做操作,其操作过程如下所示:
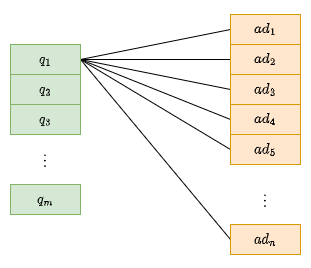
假设有个query,个ad,最终生成的query和ad对为个。
2.2.3. 主动学习Active learning
主动学习主要是用来降低样本的标注成本的学习方法,其主要思路是通过机器学习的方法获取到“难”样本,使用人工标注并将其继续放入到模型中继续学习。将主动学习应用于这里,主要是用于产出bad目标的那部分样本。
将相关性模型Relevance作为主动学习中的Teacher,计算上述个query和ad对的相关性得分,并将得分小于阈值threshold的样本挑选出来。将训练的双塔模型作为主动学习中的Student,将上述的增强数据通过双塔模型,得到CTR的预估分,根据CTR得分采样出低相关性的样本作为bad部分的样本,这部分样本标记为badCases,与曝光日志data合并为双塔的训练样本[data, badCases]。完整的流程如下图所示:
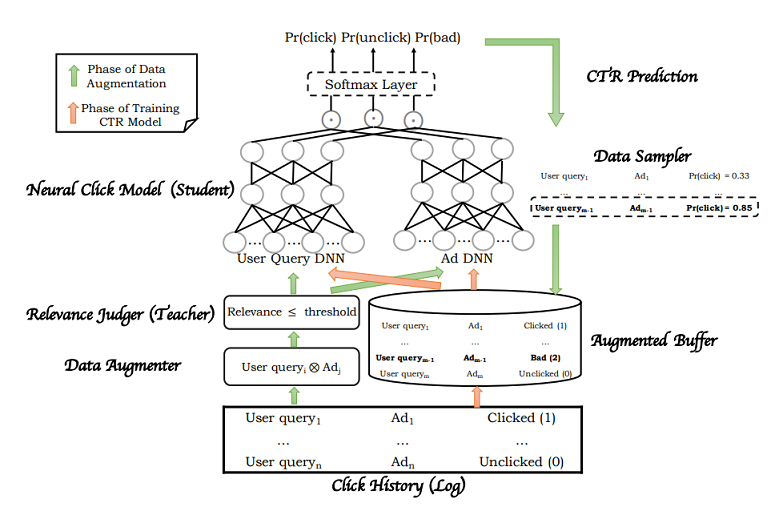
从上图中可以看到,在双塔模型中,对于User & Query侧以及Ad侧,最终都是生成了3个向量()。
2.2.4. 线上的检索过程
与其他的向量召回过程不同,在Mobius系统中,是将召回和排序合并成一个过程了,在其他系统中,向量召回只是召回环节中的一路,Mobius的线上检索过程如下图所示:
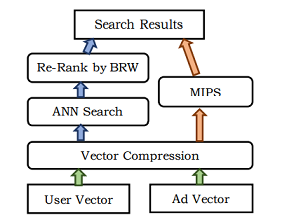
这里画出了两路,其实意思是一致的。首先对于User和Ad向量,先采用Vector Compression,即压缩的方法对其压缩以节省存储空间,后经过近似近邻搜索找到最匹配的ad,再通过business related weight(BRW)重新排序,即左侧蓝色部分。这个过程也就等价于右侧的MIPS,即:
另一个问题,这里计算向量相似性采用的是cos距离,即:
实际上是向量的乘积,但是这里需要对两个向量做归一化,因此就对应了cos距离。另外一点,在模型中,cos距离计算完后,还需要经过一个softmax层,得到对应指标的概率值,且其和为1,而概率值正比于cos距离。因此在检索阶段只需要计算click的cos值。
3. 总结
3.1. 多目标的理解
Mobius的目标是要做一个统一的模型,在这个模型中融合了召回和排序,检索出来的最终的结果是高点击且高相关性,为了完成这样的目标,一个方法是常规的多目标,画一个简单的图如下:

这是常用的多目标的建模方式,两个目标共享底层的特征以及网络参数,只是在上层的目标上有不同。在线上检索过程中需要先根据CTR分找到潜在候选,再根据相关性得分过滤。当然在这个建模的过程中还可以考虑诸如多专家等策略,详细参考[3]。
在本文中则是绕过了这个常规方法,将两个目标合并,其实通过组合有如下的几种组合:
- 高CTR,高相关(需要的,positive)
- 高CTR,低相关(bad)
- 低CTR,高相关(negative)
- 低CTR,低相关(negative)
可以发现,其实是可以将两个目标合并的,这便有了Mobius的结构。为了能得到“高CTR,低相关”这部分bad的样本,用到了Teacher-Student的主动学习。
3.2. 交叉特征
另一个问题就是双塔结构在求解CTR问题中是缺乏交叉特征的,而交叉特征对于CTR的计算是很重要的,这一点在Mobius中是没有考虑的,毕竟这也是Mobius-v1,估计会在后面的版本中继续优化吧。
参考文献
[1] Fan M, Guo J, Zhu S, et al. MOBIUS: towards the next generation of query-ad matching in baidu’s sponsored search[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 2509-2517.
[2] Huang J T, Sharma A, Sun S, et al. Embedding-based retrieval in facebook search[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 2553-2561.
[3] 多目标建模总结