1. 概述
循环神经网络(Recurrent Neural Networks, RNN)主要用于时序数据,最常见的时序数据如文章,视频等,t时刻的数据与t−1时刻的数据存在内在的联系。RNN模型能够对这样的时序数据建模。
2. 算法原理
RNN模型的基本结构如下所示(图片来自参考文献):
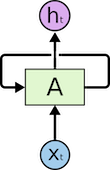
如上图所示,循环神经网络通过使用自带反馈的神经元,能够处理任意长度的时序数据,对此结构按照时间展开的形式如下所示(图片来自参考文献):
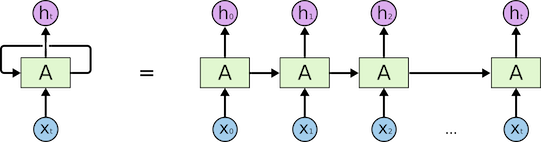
2.1. RNN的结构
上图中给出了RNN的内部结构,RNN根据输入输出主要可以分为以下三种:
- 多输入单输出,如文本的分类问题;
- 单输入多输出,如描述图像;
- 多输入多输出,又分为等长或者不等长两种情况,等长如机器作诗,不等长如seq2seq模型;
这里以多输入单输出的情况为例,多输入单输出的具体结构如下所示:
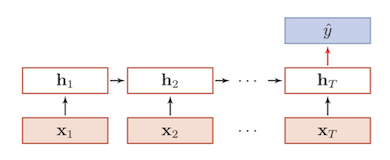
2.2. RNN的计算过程
假设对于一个长度为T的序列{x1,x2,⋯,xT},其中xi=(xi,1,xi,2,⋯,xi,n)是一个n维的向量,假设RNN的输入x的维度为n×1,隐含层状态ht的维度为H×1,RNN的状态更新公式为:
ht=f(Uht−1+Wxt+b)
通常h0会设置为全0的向量。模型中的参数U的维度为H×H,W的维度为H×n,b的维度为H×1,对于具体的分类问题,其输出为:
y^=softmax(Woht+bo)
假设对于分类问题有c个类别,则参数Wo的维度为c×H,bo的维度为c×1。最终的损失函数为:
J(U,W,b,Wo,bo)=m1i=1∑mL(y(i),y^(i))
其中
L(y(i),y^(i))=−j=1∑cyj(i)logy^j(i)
2.3. RNN中参数的求解
对于RNN模型,通常使用BPTT(BackPropagation Through Time)的训练方式,BPTT也是重复的使用链式法则,对于RNN而言,损失函数不仅依赖于当前时刻的输出层,也依赖于下一时刻。为了简单起见,以一个样本为例,此时的损失函数可以记为L(y,y^),模型的参数为U,W,b,Wo,bo,具体的求解过程如下所示:
首先对y^重新定义,样本属于第(i)个类别的预测值为:
y^(i)=∑l=1ceWolht+boleWoiht+boi
则∂Woi∂L和∂boi∂L分别为:
∂Woi∂L=−(y(i)−y^(i))ht
∂boi∂L=−(y(i)−y^(i))
假设f为tanh,而tanh(a)的导数为1−tanh(a)2,以∂U∂L为例:
∂U∂L=∂y^∂L⋅∂ht∂y^⋅∂U∂ht+∂y^∂L⋅∂ht∂y^⋅∂ht−1∂ht⋅∂U∂ht−1+⋯+∂y^∂L⋅∂ht∂y^⋅∂ht−1∂ht⋯∂h0∂h1
而∂ht−1∂ht=[1−tanh(ht)2]⋅U,这是个小于1的数,从上面的公式我们发现,时序数据越长,后面的梯度就趋于0。
2.4. RNN存在的问题
从上述的BPTT过程来看,RNN存在长期依赖的问题,由于反向传播的过程中存在梯度消失或者爆炸的问题,简单的RNN很难建模长距离的依赖关系。
参考文献
[1] Understanding LSTM Networks