1. 概述
相比较于基于Collaborative Filter算法,基于基础Graph Embedding模型可以根据用户的行为序列学习出item的embedding,利用item对应的Embedding可以方便计算item与item之间的相似度,并在实践中被证明是卓有成效的方法,在基于基础Graph Embedding模型,主要包括item2vec,node2vec,deepwalk等算法。
在使用基础Graph Embedding算法的前提是用户的行为序列,但是对于一些新的item或者用户很少有行为的item,即冷启动问题,基础的Graph Embedding算法很难学到对应item的embedding表示,为此,一些针对item冷启动的方法被提出,其中就包括GES和EGES算法。
GES和EGES是阿里在2018年提出的两个基于Graph Embedding的算法,其中GES全称为Graph Embedding with Side Information,EGES全称为Enhanced Graph Embedding with Side Information。为了解决冷启动的问题,GES和EGES在计算item embedding的过程中引入了side information。
2. 算法原理
side information在推荐系统中有着重要的作用,不仅仅能应用在召回中用于处理冷启动问题,同时在排序阶段中也有广泛的应用。side information主要指的是与item相关的一些先验信息,对于商品而言,先验信息包括:类别,商店,价格等。
2.2. GES算法
GES算法全称为Graph Embedding with Side Information,假设W表示item或者side information的embedding矩阵,其中,Wv0表示item v的embedding,Wvs表示第s个side information,item v共有n个side information,则对于item v共有n+1个向量:
Wv0,⋯,Wvn∈Rd
其中,d为embedding的维度。
对于item v,使用average-pooling将这n+1个向量聚合起来,得到item v的向量表示:
Hv=n+11s=0∑nWvs
2.3. EGES算法
EGES算法全称为Enhanced Graph Embedding with Side Information,从其名字来看便可以知道,EGES是GES的增强版。在GES中,每一个向量,包括一个item的向量以及n个side information的向量,这些向量的权重是一样的。从实际的情况来看,不同种类的side information对于最终的embedding的贡献是不一样的。因此EGES对GES中的向量做了加权的操作。
假设对于item v,权重矩阵为A∈R∣V∣×(n+1),其中,Aij表示第i个item的第j个side information的权重,为简单,记aij为Aij,Ai0表示的是item i本身向量的权重,记为ai0。
对于item v,加权平均后的结果为:
Hv=∑j=0neavj∑j=0neavjWvj
其中,使用eavj而不是avj是为了保证权重大于0。
2.4. GES和EGES的模型结构
GES和EGES的模型结构如下图所示:
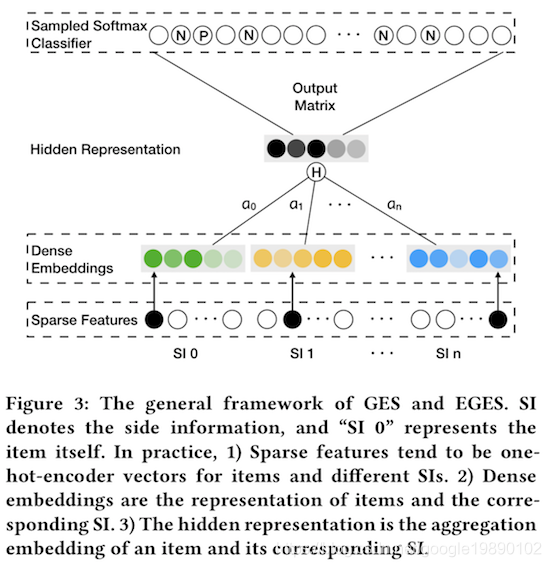
其中,Dense Embeddings表示的是item向量以及n个side information的向量。Hidden Representation即为如上公式中的Hv。从上述过程来看,GES即为EGES模型的简化版本,即权重都为n+11。
2.5. EGES中item向量的求解
EGES算法的流程如下图所示:

从EGES算法的流程中,笔者发现,其与DeepWalk的流程基本一致,不同的主要是两点:1)学习的参数不同,在DeepWalk中主要是item的向量表示,在EGES中不仅要学习item的向量W0,n个side information的向量W1,⋯Wn,还包括权重的矩阵A;2)在DeepWalk中使用的是SkipGram,在EGES中使用的是WeightedSkipGram。
2.6. Weighted Skip-Gram
Weighted Skip-Gram算法的流程如下所示:

为了能够更好的理解上述的流程,我们需要先了解word2vec中Skip-Gram模型的具体流程,在词向量的求解过程中除了Skip-Gram还可以是CBOW模型,本文的重点是Skip-Gram模型,Skip-Gram模型的结构如下图所示:

为讨论的方便,假设在Skip-Gram模型中,每个词的向量维度为d,在词典V中,中心词wc的词向量为vc∈Rd,背景词wo的词向量为uo∈Rd。给定中心词生成背景词的条件概率可以通过对向量内积做softmax运算而得到:
P(wo∣wc)=∑i∈Vexp(uiTvc)exp(uoTvc)
此时,对于整个文本可以得到如下的概率形式:
t=1∏T−m⩽j⩽m,j=0∏P(w(t+j)∣w(t))
语言模型中的目标是要使得上述的概率最大,通过log似然,可以得到如下的损失函数:
−t=1∏T−m⩽j⩽m,j=0∏logP(w(t+j)∣w(t))
对于logP(wo∣wc),有:
logP(wo∣wc)=uoTvc−log(i∈V∑exp(uiTvc))
为了能够对其中的参数求解,可以使用梯度下降法求解,此时需要对损失函数求导,以∂vc∂logP(wo∣wc)为例:
∂vc∂logP(wo∣wc)=uo−j∈V∑P(wj∣wc)⋅uj
从上述的公式发现,每次的求导数的过程中,都需要对整个词典中的词计算,如果词典较大,那么每次更新时的计算成本就比较大,为降低计算成本,近似的训练方法被提出,负采样(Negative Sampling)便是其中的一种近似计算方法。
对于上述给定的中心词wc,给定一个背景窗口,假设背景词wo出现在wc的背景窗口中的事件概率为:
P(D=1∣wc,wo)=σ(uoTvc)
对于给定的长度为T的文本,假设时间步t的词为w(t)且背景窗口大小为m,此时联合概率为:
t=1∏T−m⩽j⩽m,j=0∏P(D=1∣w(t),w(t+j))
此时模型中仅考虑了正样本,通过采样K个未出现在该背景窗口中的词,此时的联合概率为:
t=1∏T−m⩽j⩽m,j=0∏P(w(t+j)∣w(t))
其中,P(w(t+j)∣w(t))可以表示为:
P(w(t+j)∣w(t))=P(D=1∣w(t),w(t+j))⋅k=1∏KP(D=0∣w(t),wk)
可以验证,此时计算不再与词典大小相关,而是与负采样的参数K相关,以上便是Skip-Gram模型以及负采样的相关内容。
对于采样到的样本u,其对应的向量为Zu,由上述的理论可以得到:
L(v,u,y)=−[ylog(σ(HvTZu))+(1−y)log(1−σ(HvTZu))]
可以得到如下的导数:
∂Zu∂L=(σ(HvTZu)−y)Hv
∂avs∂L=(σ(HvTZu)−y)Zu(∑j=0neavj)2(∑j=0neavj)eavsWvs−eavs∑j=0neavjWvj
∂Wvs∂L=∑j=0neavjeavs(σ(HvTZu)−y)Zu
参考文献
[1] Wang J, Huang P, Zhao H, et al. Billion-scale commodity embedding for e-commerce recommendation in alibaba[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 839-848.
[2] [Graph Embedding]阿里超大规模商品Embedding策略EGES
[3] Graph Embedding在淘宝推荐系统中的应用
[4] NLP之—word2vec算法skip-gram原理详解