1. 概述
《Session-based recommendations with recurrent neural networks》首次提出将RNN方法应用于Session-based Recommendation。文章中提到当前主流的基于因子分解的模型或者基于邻域的模型很难对整个Session建模,得益于序列化建模算法的发展,使得基于Session的推荐模型成为可能,针对具体的任务,文章中设计了模型的训练以及ranking loss。
2. 算法原理
在文章中采用的GRU(Gated Recurrent Unit)序列化建模算法,这是一种改进的RNN算法,能够较好的解决RNN中的长距离以来问题。在Session-based Recommendation中,将用户登录后产生点击作为RNN的初始状态,基于这个初始状态查询后续是否会点击,其流程大致如下所示:
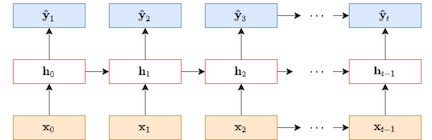
其中,作为初始状态,表示RNN的隐藏状态,表示输出,由初始状态,可以得到后续的输出。
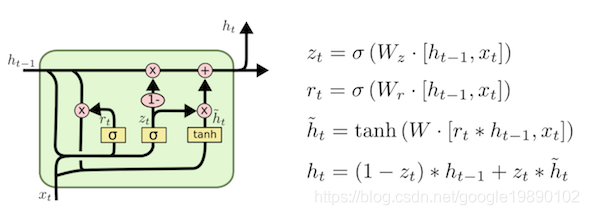
2.1. GRU
GRU全称为Gated Recurrent Unit,是RNN模型的增强版,能够有效解决RNN模型中的长距离以来问题。在GRU中,输入为前一时刻隐藏层和当前输入,输出为当前时刻隐藏层信息。GRU中包含两个门,即reset门和update门,其中用来计算候选隐藏层,控制的是保留多少前一时刻隐藏层的信息。用来控制加入多少候选隐藏层的信息,从而得到输出。GRU的结构如下图所示:
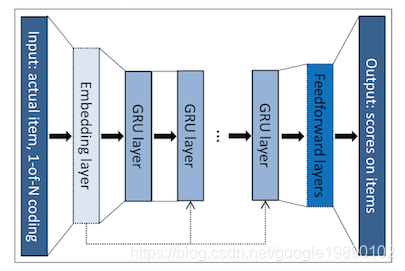
2.2. 模型结构
通过堆叠多层的GRU,可以实现对用户点击序列的建模,Session-based Recommendation的模型结构如下图所示:
在模型的损失函数方面,文章中采用了pairwise ranking losses,其中pointwise在训练过程中并不稳定。
三种ranking的方式:
- Pointwise ranking:针对的是单个样本预测得分,典型的如CTR;
- Pairwise ranking:对样本对的预测,使得正样本正样本的得分要比负样本的小;
- Listwise ranking:预测的是所有样本的得分,以得到最终的排序;
文中使用了两种基于Pairwise ranking的损失函数:Bayesian Personalized Ranking(BPR)和TOP1,其中BPR是一种矩阵分解的方法,其公式为:
其中,是样本量,是item 的分数,表示session中的正样本,表示负样本。TOP1是一种正则估计的方法,其公式为:
2.3. 模型训练
在训练的过程中,文中提出了两种策略来提高训练的效率,分别为mini-batch和负样本采样。其中mini-batch的过程如下图所示:
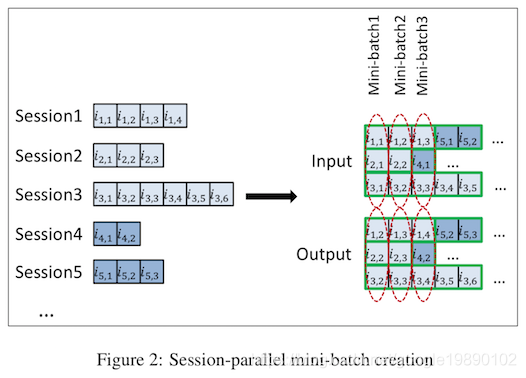
简单来讲就是将多个Session可以进行合并,但是在训练的过程中,在同一个Sequence中遇到下一个Session时,要对GRU重新初始化。
如上,从Session中得到的是正样本,但是训练的过程中不能只存在正样本,此时需要负样本,对于上图中Output中的每一位,通过在样本库中随机采样,生成负样本。
3. 实验的结论
由于我没自己做过实验,在此总结下原作者的几条结论,有待后续在工作中具体验证:
- 一层的GRU单元效果最好。作者没有给出确定的解释;
- 直接使用one-hot编码,不使用embedding;
- 使用上一时刻预测当前时刻,这并不会比使用整个session带来更多提升;
- 在GRU后面使用前馈层并不会带来提升;
- 增大GRU的size会提升效果;
- 在输出层使用tanh激活函数。
参考文献
[1] Hidasi B, Karatzoglou A, Baltrunas L, et al. Session-based recommendations with recurrent neural networks[J]. arXiv preprint arXiv:1511.06939, 2015.