1. 概述
近年来,随着深度学习在CV领域的广泛应用,人脸识别领域也得到了巨大的发展。在深度学习中,通过多层网络的连接,能够学习到图像的特征表示,那么两张人脸的图像,是不是可以通过深度学习判别其是否是相同的人呢?Google在2015年提出了人脸识别系统FaceNet[1],可以直接将人脸图像映射到欧式空间中,空间中的距离直接代表了人脸的相似度。最终,FaceNet在LFW数据集上,准确率为0.9963,在YouTube Faces DB数据集上,准确率为0.9512。FaceNet的主要优化点是:
- 通过端到端的深度学习结构将人脸映射到同一个欧式空间中,使得在映射后欧式空间中彼此之间是可度量的;
- 提出损失函数Triplet Loss,目标是使得相同人脸在欧式空间中距离较近,不同人脸在欧式空间中距离较远。
2. 算法原理
2.1. FaceNet
FaceNet的简单结构示意图如下所示:

在FaceNet中,并未直接使用预训练的CNN模型直接提取人脸特征,同时为了能够将人脸的图像映射到同一个欧式空间中且可度量,在FaceNet采用端对端对人脸图像直接进行学习,学习从图像到欧式空间的编码方法,然后基于这个编码再做人脸识别、人脸验证和人脸聚类等。
FaceNet的网络结构与传统的深度学习模型非常相似,不同的是在FaceNet中去掉了分类模型中中Softmax,取而代之的是L2归一化,通过L2归一化得到人脸的特征表示,直接将人脸的图像映射到维的欧式空间中。其中L2归一化的目的是去使得认脸的向量在同一量纲下,深度模型不是本文的重点,现如今有大量成熟的CNN模型可以直接使用,如VGG,Inception,Resnet等
2.2. Triplet Loss
Triplet Loss是FaceNet系统的另一大特点,对于认脸图像,通过Triplet Loss可以使得映射后的向量表示在欧式空间中可以度量,Triplet Loss的目标是使得相同的人脸图像在欧式空间中的向量的欧式距离相近,不同的人脸图像在欧式空间中的向量的欧式距离较远。用数学的方式方式可以表示为:假设输出人脸图像是,已称为anchor,同一个人的人脸图像,也称为positive,另一个不同人的人脸图像,也称为negative,需要使得和之间的向量距离较近,和之间的距离较远,即为:
其中,是使得正(positive)负(negative)人脸充分分开的阈值,是所有的三元组的集合,集合的大小为。训练的过程可由下图表示:
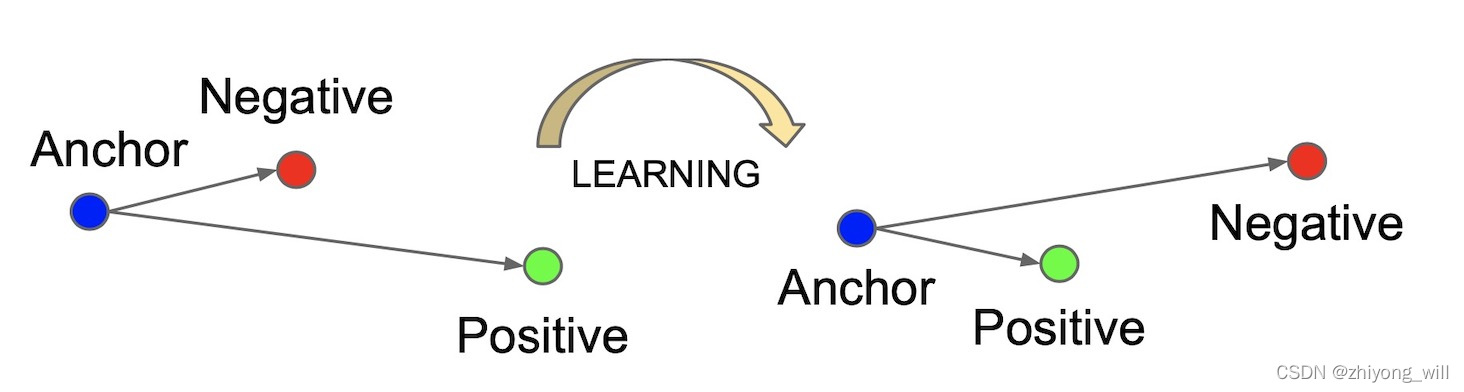
通过不断的学习,使得Anchor和Positive的距离较近,而Anchor和Negative的距离变远。对于FaceNet,其损失函数为:
2.3. 样本选择
上述三元组构成了训练集合,然而三原组的选择对模型的收敛非常重要。由上述公式可知,对于人脸图像,需要选择同一认脸的不同图像,使得
同时,还需要选择不同认脸的图像,使得
在实际训练中,对所有的训练样本来计算argmin和argmax是不现实的,还会由于错误标签图像导致训练收敛困难。参考文献[1]中给出了两种方法来进行筛选:
- 每隔步,计算子集的argmin和argmax。
- 在线生成三元组Triplets,即在每个mini-batch中进行筛选positive/negative样本。
在文献[1]中采用在线生成Triplets的方法,选择了大样本的mini-batch(1800样本/batch)来增加每个batch的样本数量。每个mini-batch中,我们对单个个体选择40张人脸图片作为正样本,随机筛选其它人脸图片作为负样本。负样本选择不当也可能导致训练过早进入局部最小。为了避免,我们采用如下公式来帮助筛选负样本:
3. 总结
在FaceNet系统中,通过端到端的训练方式将人脸图像映射到同一个欧式空间中,并通过设计Triplet Loss,使得同一人脸在欧氏空间中的距离较近,而不同人脸在欧式空间中的距离较远。
参考文献
[1] Schroff F , Kalenichenko D , Philbin J . FaceNet: A Unified Embedding for Face Recognition and Clustering[J]. IEEE, 2015.