1. 概述
RCNN(Region with CNN features)[1]算法发表在2014年CVPR的经典paper:《Rich feature hierarchies for Accurate Object Detection and Segmentation》中,这篇文章是目标检测领域的里程碑式的论文,首次提出使用卷积神经网络(Convolutional Neural Networks, CNNs)处理目标检测(Object Detetion)的问题。
2. 算法思想
2.1. RCNN算法流程
RCNN算法的流程图如下所示:
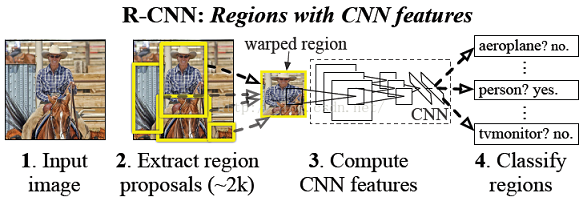
从图中可以看出,RCNN主要包括三个部分:
- 区域提名(Region Proposal):使用到了Selective Search[2]的方法,通过Selective Search的方法产生约2000个目标可能出现的位置。在参考[3]中分别给出了C++和Python的实现;
- 特征计算:特征计算阶段使用CNN算法,文章中使用AlexNet卷积神经网络,首先裁剪出上述2000个目标可能出现的位置的图像,并将其reshape成,最后通过AlexNet进行特征计算,得到4096维的特征向量;
- 分类算法:分类阶段是单独训练了SVM的分类器,对每一个类别训练一个二分类的分类器(yes/no)。
针对于候选区域的reshape过程,在参考[4]中做了详细的分析,如下图所示:

分析了三种的reshape方法,分别为:
- tightest square with context
- tightest square without context
- warp
2.2. 几个重要的概念
2.2.1. IoU
IoU(Intersection-over-Union),即交并比。是目标检测中使用到的一个重要概念,是一种测量在特定数据集中检测相应物体准确度的一个标准。IoU表示的是预测的候选框(candidate bounding box)与原标记框(ground truth bounding box)的交叠率(或者重叠度),也就是它们的交集与并集的比值。相关度越高该值。最理想情况是完全重叠,即比值为1,如下图所示:
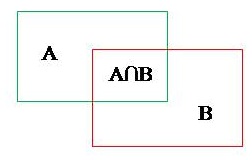
那么,IoU的计算公式为:
2.2.2. 边框回归Bounding Box Regression
在RCNN中,使用边框回归的目的是提高检测位置的准确性。那么,Bounding Box Regression具体如何做呢?在参考[2]中给出了Bounding Box Regression的具体做法:假设数据集中有个训练数据,其中表示的是预测的边框,且,和表示的是边框中心点的坐标,和表示的是边框的宽高。表示的是实际的边框,其结构与一致。我们的目标是寻找到一个映射,使得,同时。
在RCNN中,边框回归是利用平移变换和尺度变换实现的。其中,平移变换为:
尺度变换为:
其中,可以建模成特征(在RCNN中为,可以表示为)的线性函数,即:,我们需要学习到参数,可通过对求解如下的最小化问题,得到对应的解:
其中,目标可以由上述的两个变换得到:
2.2.3. 非极大抑制NMS
非极大抑制NMS(non maximum suppression),从其名称就可以看出,NMS想要做到的是找到局部的极大值,抑制非极大值,主要用于在图像检测中剔除掉检测出来的冗余的bbox。对于目标检测算法,最终我们会得到一系列的bbox以及对应的分类score,NMS所做的工作就是将同一个类别下的bbox按照分类score以及IoU阈值做筛选,剔除掉冗余的bbox,NMS的具体过程为:
- 在算法得到一系列bbox后,按照类别划分;
- 对于每一个分类,根据分类score对该类别下所有的bbox做降序排列,最终得到一个排好序的列表list_i;
- 从列表list_i中取出最大score的bbox_x,并将其与list_i中所有其他的bbox_y计算IoU,若IoU大于某个阈值T,则剔除bbox_y,最终保留bbox_x;
- 从剩余的list_i中重复上述的选择操作,直到list_i中的bbox都完成筛选;
- 对其余的类别的列表重复上述两步的操作。
2.3. RCNN模型的训练
在模型训练之前,首先需要的是训练数据集,文章中使用的是VOC数据集,数据集中包含了20个类别的物体。RCNN模型的训练需要分为几个部分单独计算,按照上述流程,分为三个部分:
- Region Proposal:对于训练集中的所有图像,使用selective search对每张图像提取出约2000个region proposal,将提取出的region proposal保存在本地。
- AlexNet的特征计算:通常,CNN模型都会使用到预训练模型,同样,这里使用的AlexNet模型也是在ILSVRC 2012上预训练的模型。针对此处的训练数据集,需要对模型Fine-tuning。针对Fine-tuning过程中使用到的数据集,对于一个region proposal,如果其和图像上的所有ground truth中交并比IoU大于等于0.5,则该region proposal作为这个ground truth类别的正样本,否则作为负样本,此外。ground truth也作为正样本。因为VOC一共包含20个类别,另外还包括背景,所以这里region proposal的类别为21类。在此数据集上对CNN模型进行Fine-tuning。
- 对于每一个类别训练SVM模型:利用CNN模型,对2000个region proposals提取特征,得到的特征,对于每一个类别训练一个SVM模型。此处的训练样本与特征计算过程中不一致,这里IoU<0.3的是负样本,Ground Truth是正样本。
- 边界框回归:得到AlexNet的特征和bounding box的ground truth来训练bounding box regression,只对那些跟ground truth的IoU超过某个阈值的proposal进行训练,其余的不参与,从而对proposal的边框修正。
2.4. RCNN模型推理
在推理阶段(测试阶段),对于一张待检测图片,主要分为以下几个部分:
- 使用Selective Search提取出约2000个region proposals;
- 将每一个region proposal缩放到AlexNet需要的大小,即,通过AlexNet对每一个region proposal计算出4096维特征;
- 对于每一个类,使用对应的SVM分类器计算出对应类别的概率,使用非极大值抑制(为每个类别单独调用),然后去掉一些与高分被选区域IoU大于阈值的候选框;
- 利用边框回归对最终的边框修正;
3. 模型存在的问题
RCNN的提出对于目标检测领域来说是个里程碑式的进步,但是RCNN算法中存在许多的不足,从上述流程可以发现,可以发现:
- 过程太多,而且较为分散,同时需要存储中间的计算结果(region proposals以及每一个region proposal的CNN特征);
- 存在重复的计算,每一个region proposal都需要计算CNN特征;
参考文献
[1] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
[2] Uijlings J R R, Van De Sande K E A, Gevers T, et al. Selective search for object recognition[J]. International journal of computer vision, 2013, 104(2): 154-171.
[3] Selective Search for Object Detection (C++ / Python)
[4] JitendraMalik R G J D T D. Rich feature hierarchies for accurate object detection and semantic segmentation Supplementary material[J].
[5] 【计算机视觉——RCNN目标检测系列】一、选择性搜索详解