1. 概述
蒸馏是一个化学上的词汇,百科上对于蒸馏的解释为:“蒸馏是一种热力学的分离工艺,它利用混合液体或液-固体系中各组分沸点不同,使低沸点组分蒸发,再冷凝以分离整个组分的单元操作过程,是蒸发和冷凝两种单元操作的联合”。原理如下图所示:
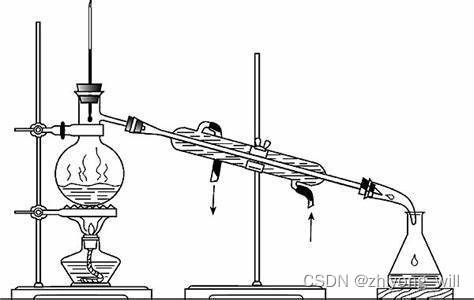
蒸馏的目的是在不同的温度下提出了特定的成分。说回到知识蒸馏(knowledge distillation),其是模型压缩的一种常用的方法,最早得到推广的版本是由Hinton在2015年[1]提出并应用在分类任务上。与蒸馏的目的一致,在知识蒸馏中,希望通过提取性能更好的大模型的监督信息,构建一个小模型,同时使得小模型具有较好的性能和精度,而此处的大小模型成为Teacher,小模型称为Student。
2. 知识蒸馏的基本原理
2.1. 知识蒸馏原理
随着计算能力的不断提升,现在的模型也越来越大,网络也越来越深,结构变得异常复杂,这带来了模型准确率的提升,同时,计算复杂度也随之提升。知识蒸馏就是一种有效的模型压缩的方法,同时能够使得压缩后的模型的效果并未下降太多。
在知识蒸馏中,首先需要有一个大模型,也称为Teacher模型,该模型的特点是模型复杂,此时需要对该模型压缩,得到一个较小的模型,也称为Student模型,在蒸馏的过程中,将Teacher模型中学习到的“知识”迁移到Student模型中,以使得Student模型具有与Teacher模型一致的效果。具体的过程如下图所示:
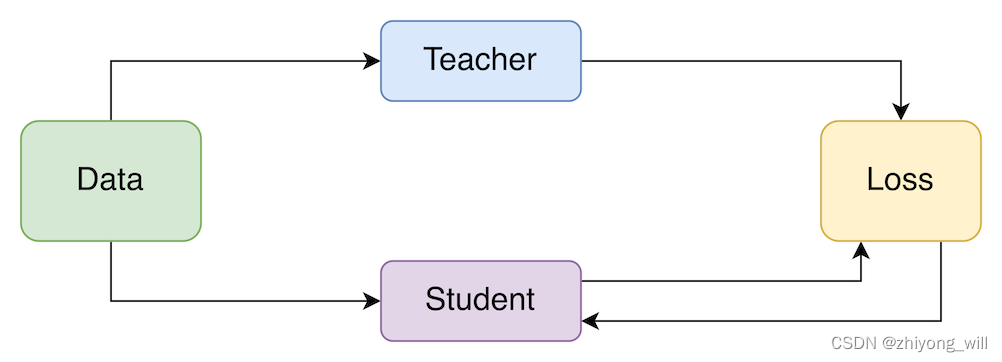
2.2. 知识蒸馏学习过程
对于一个完整的知识蒸馏过程,有两个模型,分别为Teacher模型和Student模型,通过学习将已经训练好的Teacher模型中的知识迁移到小的Student模型中。其具体过程如下图所示[2]:

对于Student模型,其目标函数有两个,分别为蒸馏的loss(distillation loss)和自身的loss(student loss),其最终的损失函数为:
其中,为student模型自身的损失,对于分类问题来说,可以通过交叉熵计算:
其中,为样本的真实标签,对于分类问题来说即为0或者1,为Student模型的输出。通常,可以通过softmax计算得到:
对于softmax的计算,是在网络的logits结果上,在softmax计算后得到的概率分布毁放大logits,会使得类目之间的差异变大。因此在知识蒸馏中,通常在logits的基础上加上一个温度变量,来对logits结果缩放:
当时即为正常的输出,上述的即在的情况下计算得到。对于的计算,通常有两种方式,一种是计算softmax输出结果的差异,另一种是直接比较logits结果的差异。
对于softmax结果的差异,由于softmax的结果是概率分布,因此可通过交叉熵计算分布之间的差异:
其中,为Teacher模型的输出,为Student模型的输出。且输出是在的情况下计算得到。
对于logits结果的差异,可以直接比较Teacher网络和Student网络输出logits的平方差,即:
其中,为Teacher模型的logits输出,为Student模型的logits输出。
3. 总结
知识蒸馏通过对Teacher模型的压缩得到效果接近的Student模型,由于网络模型复杂度的减小,使得压缩后的Student模型的性能得到较大提升。
参考文献
[1] Hinton G , Vinyals O , Dean J . Distilling the Knowledge in a Neural Network[J]. Computer Science, 2015, 14(7):38-39.