1. 概述
随着BERT模型的提出,在NLP上的效果在不断被刷新,伴随着计算能力的不断提高,模型的深度和复杂度也在不断上升,BERT模型在经过下游任务Fine-tuning后,由于参数量巨大,计算比较耗时,很难真正上线使用。这些基于Transformer模型的提出,包括BERT,GPT等,那么对于传统的NLP方法,如RNN,LSTM,TextCNN是不是就已经过时了呢?结合知识蒸馏的思想,Distilled BiLSTM[1]将BERT模型当作Teacher模型,对Fine-tuned BERT进行蒸馏,使得蒸馏得到的Student模型BiLSTM模型与ELMo模型具有相同的效果,但是参数量却减小了100倍,同时,计算时间缩短了15倍。
2. 算法原理
2.1. 知识蒸馏
知识蒸馏(knowledge distillation)[2]是模型压缩的一种常用的方法,对于一个完整的知识蒸馏过程,有两个模型,分别为Teacher模型和Student模型,通过学习将已经训练好的Teacher模型中的知识迁移到小的Student模型中。其具体过程如下图所示:
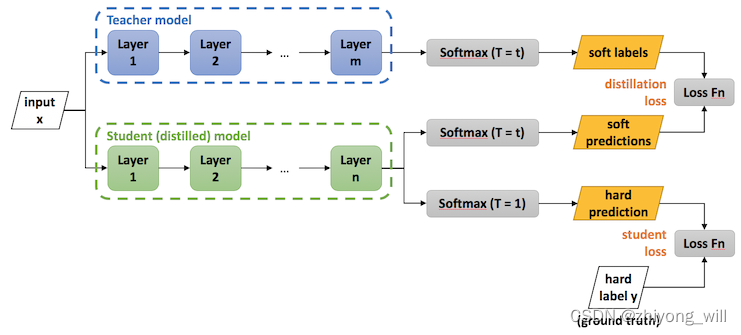
对于Student模型,其目标函数有两个,分别为蒸馏的loss(distillation loss)和自身的loss(student loss),Student模型最终的损失函数为:
2.2. Distilled BiLSTM
在对BERT蒸馏过程中,选择了两个特定的任务,一个是分类任务,另一个则是句子对任务。
2.2.1. Teacher模型
在Distilled BiLSTM,Teacher网络为Fine-tuned BERT模型,BERT模型的结构如下图所示:
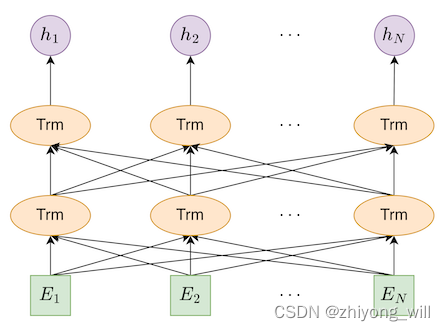
假设BERT模型对句子抽取出的向量为。对于单句的分类任务,增加一个输出层即可:
其中,,为分类的个数。对于句子对,则是采用上述的方法对每个句子计算,计算完将两个特征concat在一起,再经过上述的softmax计算。
2.2.2. Student模型
在Distilled BiLSTM中,Student模型为一个单层的BiLSTM模型,BiLSTM网络结构如下图所示:
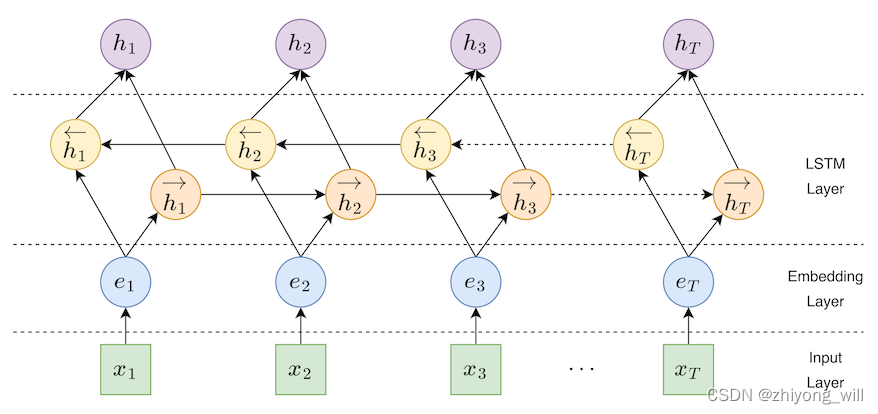
在分类任务中,参考文献[1]中将最后一个隐层状态concat在一起,即上述的,后续经过一个输出层得到最终的输出,具体的网络结构如下图所示:
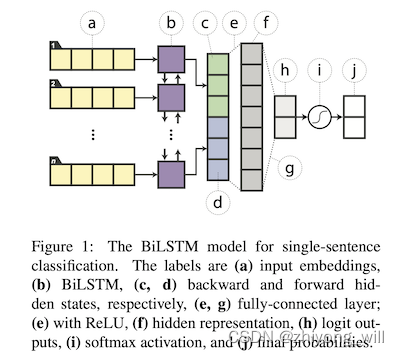
其中,上图中的c和d表示的是将前向和后向的隐层状态concat在一起,上图中的e和g表示的是一个全联接层,e的激活函数是ReLU。对于句子对的任务,利用BiLSTM分别产出句子向量,并将两个向量合在一起,后续的处理方法与单句的处理方法相同,具体的网络结构如下图所示:
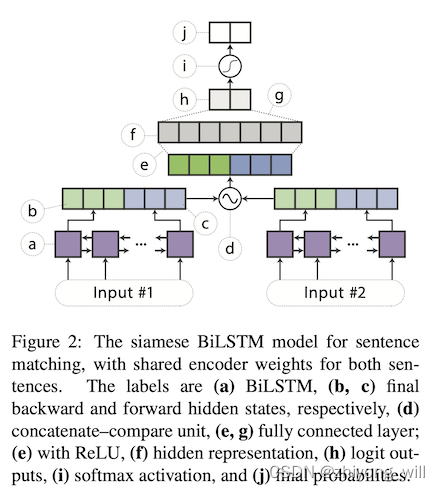
对于句子对特征的组合,在参考文献[1]中,其处理方法为:
其中,表示的是向量元素相乘。
2.2.3. 蒸馏目标
对于知识蒸馏的目标函数,其包含两个部分,一个是蒸馏的loss(distillation loss)和Student模型自身的loss(student loss)。对于Student模型自身的loss采用的是交叉熵作为分类问题的目标函数,对于蒸馏的loss,则是采用对比logits结果的差异:
其中,为BERT模型的logits输出,为Student模型的logits输出。最终的蒸馏目标为:
3. 总结
Distilled BiLSTM是对于知识蒸馏较为一般性的实践,将BERT模型(Teacher)蒸馏到一个简单的BiLSTM模型(Student),蒸馏的目标函数中的蒸馏loss也是采用了对比logits结果的差异。虽然理论上较为简单,但是最终的结果是与与ELMo模型具有相同的效果,说明知识蒸馏的方法的有效性。
在BiLSTM中,多个隐层状态的融合有不同的方法,如上面直接用最后一个隐层状态作为最终的状态,实际上,可以使用Attention的方法综合多个隐层状态作为最终的状态能够进一步增强模型的效果。
参考文献
[1] Tang R , Lu Y , Liu L , et al. Distilling Task-Specific Knowledge from BERT into Simple Neural Networks[J]. 2019.
[2] 知识蒸馏基本原理