1. 概述
通常在卷积神经网络CNN中主要是由卷积层(包括Convolution和Pooling两部分组成)和全连接层组成,对于任意一张大小的图片,通常需要通过裁剪或者拉伸变形的方式将其转换成固定大小的图片,这样会影响到对图片的识别。Kaiming He等人在2015年提出了Spatial Pyramid Pooling的概念[1],通过Spatial Pyramid Pooling操作后的CNN网络消除了对输入图像大小的限制,这样能够提升网络对图像的识别能力。
2. 算法原理
2.1. 固定大小的输入
在一般的CNN结构中,通常是由卷积层和全连接层组成的,卷积层中的Convolution和Pooling是采用的滑动窗口的方式对特征图进行计算,因此这两个操作不要求固定的输入的大小;而全连接层的特征数是固定的,所以在网络输入的时候,会要求具有固定的输入大小,以一个通道,单个卷积层和全连接层为例,如下图所示:
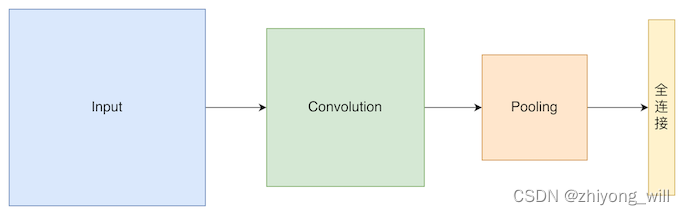
假设输入大小为,卷积核大小为,paddding为,步长为,则卷积操作的输出大小为,Pooling的大小为,步长为,则Pooling操作后的输出大小为,则全连接的输入为。
如果输入的大小变成,卷积操作的输出大小为,Pooling操作的输出大小为,则全连接的输入为,这样全连接层就不能工作了,因为全连接层的参数个数上下两种情况下并不统一。
针对上述问题,通常的做法是对原始图片裁剪或者拉伸变形的方式将图片变换到固定大小,如下图所示:
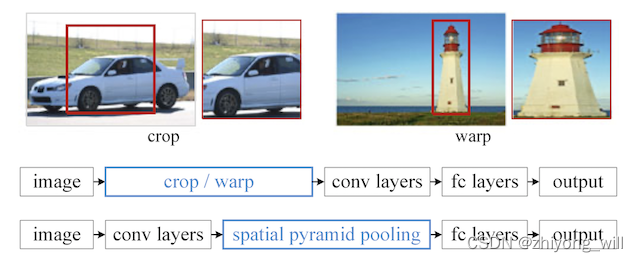
这样的变换操作使得原始的输入图像被改变,会扭曲原始的图像。由于是在全连接层出现了问题,因此只需要在全连接层增加一个层,能够将任意大小的特征图转换成固定大小的特征图,这样就能解决任意大小图像的输入问题。在[1]中提出了Spatial Pyramid Pooling层的概念,其过程如上图所示。
2.2. Spatial Pyramid Pooling Layer
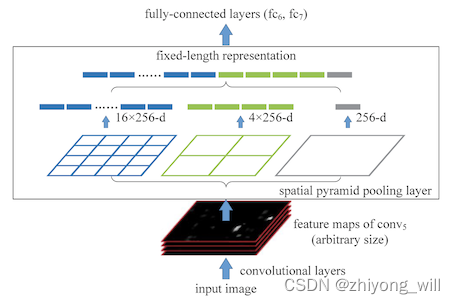
为了应对不同大小的输入问题,在CNN网络的卷积层和全连接之间增加一个空间池化层(Spatial Pyramid Pooling Layer),对于每一特征图,采用不同尺度的Pooling操作,对于一般性的max-pooling操作如下图所示:

通过窗口大小为,步长为的max-pooling操作,将尺寸大小为的特征图转换成的特征图,那么如果对于输入的特征图大小为,要使得输出的特征图大小依然为,那么窗口的大小就得是,且步长为。与原始的Pooling操作不同的是原先的Pooling操作是固定好窗口大小和步长,而此处的Pooling操作是固定好想要的输出大小,那么输入,输出以及窗口,步长之间的关系为:
其中表示的是输入的特征图的大小,表示的是输出的特征图的大小。表示的是向下取整,表示的是向上取整。在Spatial Pyramid Pooling层中,为了能够对任意输入大小的特征图能得到固定大小的输出,可以采用上述动态的窗口大小和步长,为了能够得到不同尺度下的特征,可以设计不同大小的输出,如下图中设计了三种大小的输出,分别为,和,具体如下图所示:
3. 总结
针对不同大小的输入图像,在传统CNN网络中,需要首先将图像通过裁剪或者拉伸等变换转换到固定大小,通过分析,不同尺寸的输入主要是对全连接层有影响,SPP-Net中,在全连接层之前引入Spatial Pyramid Pooling Layer,可以将任意大小的输入转换成固定大小的输出。
参考文献
[1] He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916.