1. 概述
在现如今的推荐系统或者搜索中,都存在多个目标,多目标的算法在现如今的系统中已然成为了标配。在多目标的建模过程中,如果不同的学习任务之间较为相关时,多个任务之间可以共享一部分的信息,这样最终能够提升整体的模型学习效果。但是如果多个任务之间的相关性并不强,或者说多个任务之间存在某种冲突,这样通过部分的共享就会起到事与愿违的效果,这便是通常所说的在多任务建模中出现的负迁移(negative transfer)现象,即在相关性不强或者无相关性的多任务环境下进行信息共享,最终影响整体的网络效果,MMoE[1]便是在这样的情况下被提出。在MMoE中,通过共享多个专家(expert)实现信息的共享,同时针对每一个上层任务(task)都有对应的门控函数(gate),学习到多个专家对于特定任务的贡献程度,即专家的分布。以此,实现了对任务之间的关联和区别的学习。
然而,在多任务建模过程中,还存在另外一种现象,称为跷跷板现象(seesaw phenomenon)。简单来说,跷跷板现象就是在对多个目标进行优化的过程中,一个任务指标的提升伴随着另外一些任务指标的下降。出现这种现象的主要原因是多个任务之间出现较多的共享,MMoE算法中也不能有效解决这样的一个问题。PLE(Progressive Layered Extraction)[2]模型在MMoE的基础上通过对共享的网络结构优化,在原先的共享部分,又增加了task-specific的部分,同时,为了增强网络的效果,构造了多层的网络结构。
2. 算法原理
2.1. Customized Gate Control
为解决上述提出的两个问题,参考[2]中首先提出了CGC(Customized Gate Control)网络。在CGC网络中,在共享专家网络的基础上,又针对特定的任务有特定的专家网络,以此增强每个任务的效果。CGC的网络结构如下图所示:
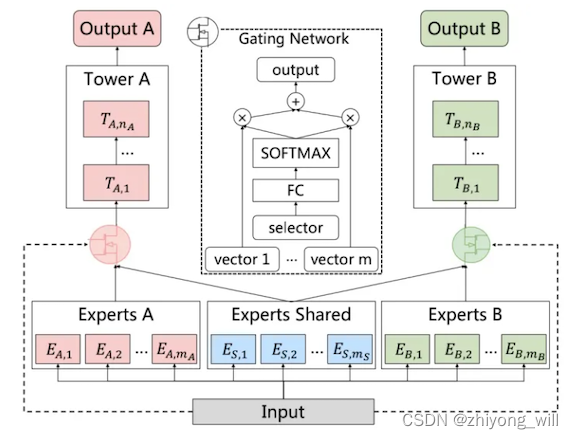
在CGC的网络结构中,其底层网络包括了shared experts和task-specific expert两个部分,且每一个expert部分都是由多个expert组成,上层针对每一个任务都有一个门控网络,且门控网络的输入是共享的experts和该任务对应的experts。由此可见,在CGC网络中,既包含了task-specific网络针对特定任务独有的信息,也包含了shared网络共享的信息,以上图为例,假设为指定任务对应的多个专家的输出,为共享部分的多个专家的输出,这两个输出组合成上层门控网络的输入:
门控网络的计算输出为:
其中,,且。
2.2. Progressive Layered Extraction
在深度学习中,为了使得模型能够具有更好的泛化能力,通常的方法是构建更深的网络。同样,为了能够得到更具有泛化能力的网络,可以将上述网络构建得更深,这便有了PLE结构。简单来说,PLE结构可以看做是CGC网络结构的扩展,由single-level的CGC衍生为multi-level的PLE。具体的PLE网络结构如下图所示:
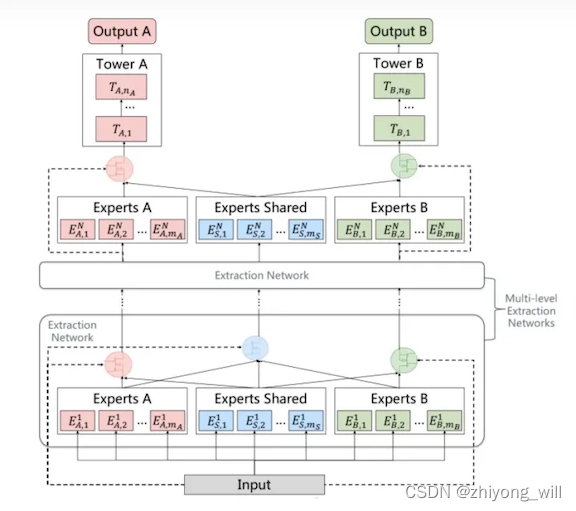
与CGC网络相比,除了第一个Extraction Network的输入是原始的Input,其余的Extraction Network的输入是上一个Extraction Network的输出,即包含两个大的部分,即特定任务对应的专家网络输出,如上图中的Experts A和Experts B的输出,另外一个是共享专家网络的输出,如上图中的Experts Shared的输出。
2.3. 损失函数
在多任务重,其损失函数为各任务损失的加权求和,即为:
其中,为第个任务的权重,对于权重的设置,参考[2]中给出了如下的迭代公式:
其中,为更新率。对于任务的损失函数,参考[2]中给出了如下的公式:
因为存在不同任务上的样本空间不一致的问题,因此在特定的任务中计算损失函数时,选择在其空间上的样本,即对于,其取值为或者,表示的是第个样本是否属于第个任务的样本空间。
3. 总结
为了解决多任务模型中普遍存在的负迁移和跷跷板现象,在MMoE模型的基础上提出了CGC模型,在共享专家的基础上增加了针对特定任务的专家网络,可以针对特定任务学习到独有的网络部分,从而避免任务之间的相互影响,同时为了进一步提升整体网络的泛化效果,在CGC的基础上通过堆叠Extraction Network构造了更深的网络结构,进一步提升多任务模型的学习效果。
参考文献
[1] Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1930-1939.
[2] Tang H, Liu J, Zhao M, et al. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations[C]//Fourteenth ACM Conference on Recommender Systems. 2020: 269-278.