1. 概述
对于一个搜索系统来说,通常采用的召回都是基于倒排索引的召回,简单来说就是需要对item侧建立倒排索引,在检索的过程中,对query分词,根据分词结果去倒排索引中查找词匹配的item,简单的流程如下图所示:
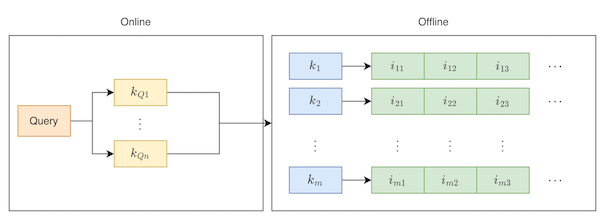
在传统的检索过程中,通常存在语义上的问题,比如Query为“连衣裙”,此时根据词匹配就检索不到核心词为“长裙”的item,为了解决这样的问题,需要对Query进行扩展,将其扩展成相似的query,以此来实现语义匹配的问题。当然,词匹配的方式的一大优势就是相关性解决的比较好。为了能从算法上解决语义的gap,双塔的召回结构是现如今较多采用的一种方法。
双塔的召回有如下的一些优势:
- item侧可离线计算,线上可采用基于ANN的向量匹配方式较快的查找到向量空间与Query相匹配的item
- 基于模型的方法,可以融入更多的特征
基于这样的优势,京东也提出了自己的向量召回算法DPSR(Deep Personalized and Semantic Retrieval)[1],着重解决两个方面的问题,第一是语义相关而并非严格的词匹配;第二是提供更多的个性化。
2. DPSR的算法原理
2.1. DPSR的模型结构
DPSR的模型结构如下图所示:
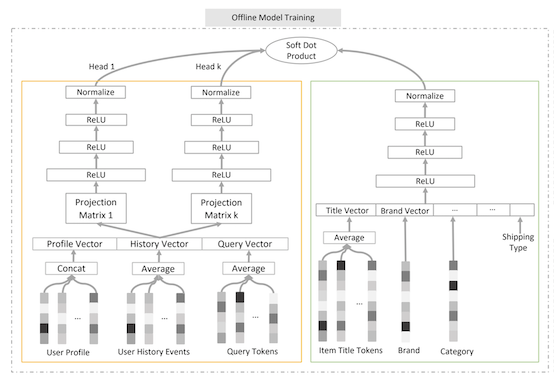
从上面的DSPR模型结构来看,与传统的双塔结构并没有太多的不一致,只是在Query和User侧设计了多向量的结构,这一点与MIND[2]算法倒是有点类似,只是方法上略有区别,其主要的目的就是用户刻画用户的多兴趣表示。
假设用表示query侧的塔输出的个维的向量,表示的是item侧的塔输出的个维的向量,基于上图中,其中。最终相似度的计算方法为:
为了实现个向量的输出,这里采用了Projection层(实际上可以理解成个投影矩阵),与MIND[3]中使用动态路由的方式有点不同。
2.2. 模型的训练
假设query塔的输出为,其中,item侧塔的输出为,两个塔之间的相似性计算为:
其中是一个权重的表示,其具体计算方法为:
其中是一个温度参数。
温度参数在较多计算softmax的场景下有涉及,如知识蒸馏[3]中,其主要作用是控制softmax的输出的“平滑程度”。简单对其分析可以发现,当越大,结果就越平滑;反之,得到的概率分布就越尖锐。
这里的做法与Label-aware Attention的做法相似。除了上述的相似性的计算外,在DPSR中选择的样本为正负样本对的形式,即:
对应的损失函数就是hinge loss:
2.3. 样本选择
负样本的选择一直是双塔召回模型中最重要的一块内容,对于正样本没有争议,通常选择点击样本作为正样本,而对于负样本通常有两种策略:
- 根据频次从全库中随机采样
- batch内的随机采样
这是随机样本的部分,通常还会增加一些困难样本,主要有人工的挖掘以及在线的困难样本挖掘。在DPSR中则是将负样本分成了两个部分,分别为随机负样本和batch负样本。
在DPSR中,随机负样本的选择就是简单的随机采样,并没有考虑到样本的频次问题。从全库的个item中得到随机的负样本;Batch负样本是在Batch内通过重组得到负样本,在Batch内,本身是正样本的集合,针对第个样本,与其他样本重组得到batch负样本的集合,其实batch内的这些负样本与根据item的频率采是等价的。
最终,在DPSR中通过一定比例混合了两部分的负样本:
当然在实验中也设置了不同的混合比例,设置为取random负样本的概率,则便是取Batch负样本的概率。通过下面实验的截图也能看到不同的对效果的影响:

最终选择的值为或者。
除了上述的随机样本之外,DPSR中也用到了一些人工的挖掘样本,主要包括以下的几类:
- Most skipped items
- Human generated data
- Human labels and bad case reports
这些样本的挖掘对于模型的效果是很重要的,综上,DSPR的训练流程如下图所示:

3. 总结
这篇文章的设计相对而言比较简单,有点亮点的地方就是设置了个兴趣向量,并且在计算的过程中也是考虑到了Label-aware Attention的计算,但是主要有如下的几点没有交待的清楚:
- 的设置,文章并未对的设置做试验性的分析,在MIND中有对的设置的分析;
- 相关性的分析,众所周知,在搜索系统中增加向量召回,一个很大的问题就是相关性问题,在文章中只是在的设置那部分提到了相关性;
另外,基于本人在工作中的一些经验,是否上个性化,个人觉得要看业务的现状,若是召回本身就是不足的,那么上不上个性化意义不是特别大,而是要解决召回不足的问题,个性化是在进一步提高转化效率。
参考文献
[1] Zhang H, Wang S, Zhang K, et al. Towards personalized and semantic retrieval: An end-to-end solution for e-commerce search via embedding learning[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2020: 2407-2416.
[2] Li C, Liu Z, Wu M, et al. Multi-interest network with dynamic routing for recommendation at Tmall[C]//Proceedings of the 28th ACM international conference on information and knowledge management. 2019: 2615-2623.
[3] 知识蒸馏基本原理