1. 概述
RoBERTa[1],全称是 A Robustly Optimized BERT Pretraining Approach,从名字来看是 BERT 的增强版。模型结构与 BERT 完全相同,不同的是在模型的训练上,通过对 BERT 的训练过程的优化,进一步的提升下游任务的表现,且相较于 BERT 来说具有更强的鲁棒性。
相比较于 BERT 模型的训练过程,在 RoBERTa 中,主要的改进点如下:
- 摒弃静态 mask,改成动态 mask
- 移除了 NSP 训练任务
- 使用了 BBPE 的分词方法
- 更多的训练数据,同时增大训练步数、Batch Size 等
2. 动态 Mask(Dynamic masking)
Mask 是在 BERT 模型训练中提出的一种训练方法,指的是将一些词替换成 [MASK],并在训练的过程中,通过上下文信息来预测被 Mask 的词,这也就是模型被称为 Masked Language Model 的原因。
然而,在 BERT 模型中,采用的是随机替换的策略,且替换的概率为 15%,同时,随机选择又分为如下的三种情况:
- 80% 替换成 [MASK]
- 10% 随机替换
- 10% 保持不变
然而上述的替换策略在 BERT 中是在数据预处理时做的,一旦固定好 Mask 的位置后将不再改变。也就是说,在训练的过程中,每个 epoch 中的训练集中的相同句子的 Mask 是不变的,是静态的。
针对这种静态的 Mask 策略,在 RoBERTa 中提出了两种改进的策略:
- 改进的静态Mask:先将训练数据复制 10 份,再进行 Mask 操作,从而让每个句子在多轮训练过程中有 10 种随机的 Mask。
- 动态Mask:每轮训练都进行一次 Mask 操作,从而使得每个句子在被输入到模型中时都有不同的 Mask 结果。
3. 移除了 NSP 训练任务
在 BERT 模型的预训练过程中,主要有两个训练任务,其中之一是上述的 MLM,另一个就是 NSP(Next Sentence Prediction),简单来说,NSP 任务就是将两段文字拼接到一起输入到模型中,让模型判断输入的两段文字是否连续,示意图如下所示:

在 BERT 中,NSP 任务被假设的很重要。然而,越来越多的工作质疑了 NSP 任务的必要性,发现其损害了预训练模型的性能。在 RoBERTa 中,作者提出了以下四种训练方式:
- Segment-Pair(段落) + NSP:与 BERT 的输入形式一样。输入由两个来自同一文档的连续段落或者不同文档的段落拼接而成。每个段落可以包含多个句子,但是输入总长必须小于 512 个 Token。
- Sentence-Pair(句子) + NSP:输入由两个来自同一文档的连续句子或者不同文档的句子拼接而成。因为输入总长远小于 512 个 Token,所以适当的增加 batch size 从而使得一个 batch 里的 token 总数与 Segment-Pair + NSP 方式相当。
- Full-Sentences: 输入由一篇或多篇文档的连续句子组成,不同文档之间使用 [SEP] 分隔,输入总长最多 512 个 token。
- Doc-Sentences:输入构建方式和 Full-Sentences 类似,但是仅由一篇文档中的连续句子组成。由于从一篇文档结尾部分采样的输入长度比 512 短,因此需要在这些样本中动态增加 batch size 才能使得一个 batch 里的 token 总数与 Full-Sentences 方式相当。
通过以上机组实验,有如下的一些实验数据:
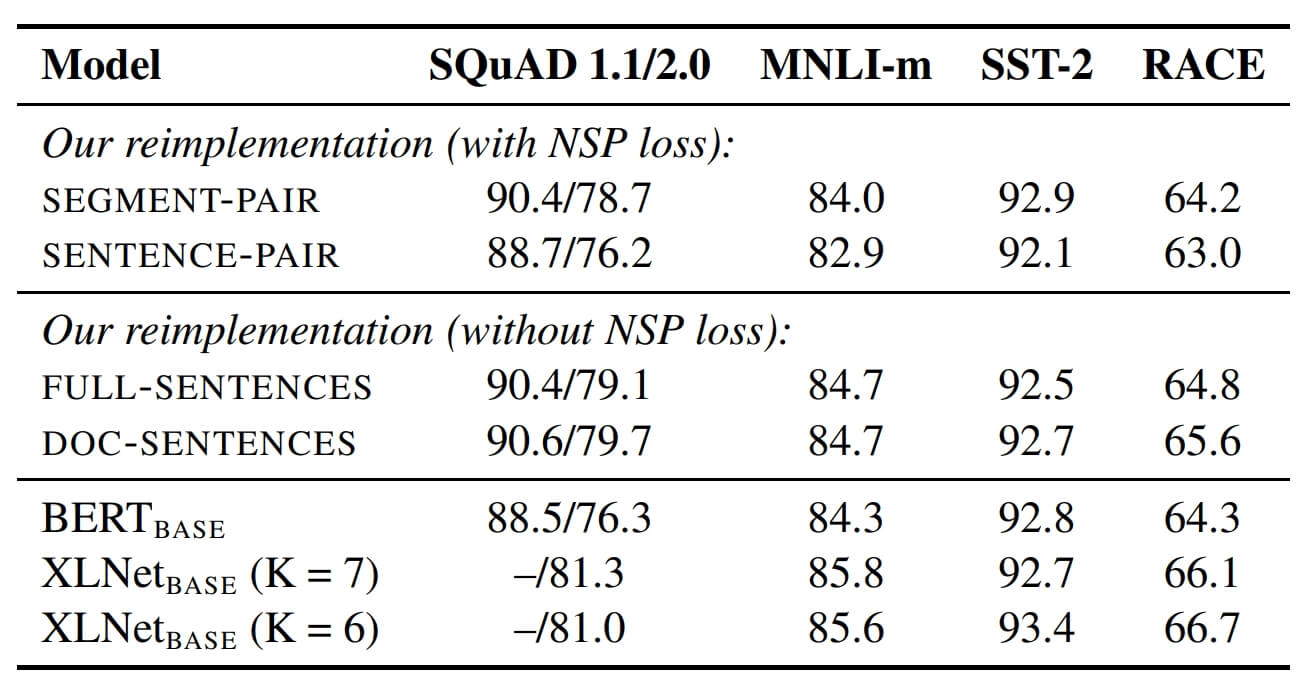
对比结果表明:Doc-Sentences 最优,Full-Sentence 略低,而 Sentence-Pair + NSP 表现最差。
4. 使用了 BBPE 的分词方法
在 BERT 中分词采用的是一种称为 WordPiece 的方法,简单来讲,WordPiece 就是将词拆分成一片一片,是一种介于字符(character)和词(word)粒度之间的一种分词方法。BPE(Byte-Pair Encoding)是 WordPiece 的一种实现方式,通过将词分成一个一个的字符,然后在词的范围内统计字符对出现的次数,每次将次数最多的字符对保存起来,直到循环次数结束。BPE 的词表是通过对语料库进行统计分析抽取得到的,词表大小一般在 10K-100K,使用子词粒度可以有效缓解“未登录词”的情况。
BBPE(Bytes-level BPE)是对 BPE 分方法的一种改进,其基于 Unicode 字符集使用 UTF-8 字符编码方式,使用字节来替代 BPE 方法中的字符作为构建子词的最小单元。BBPE 方法的词表大小一般在 50K 左右,可以在不引入任何未知词语的情况下对任何输入进行编码。
5. 更多的训练数据,同时增大训练步数、Batch Size 等
这部分属于模型参数调优,因为作者看到了一些文章在增大 Batch-Size 会对结果有提升,于是就做了 Batch-Size 调优,直接看实验数据:
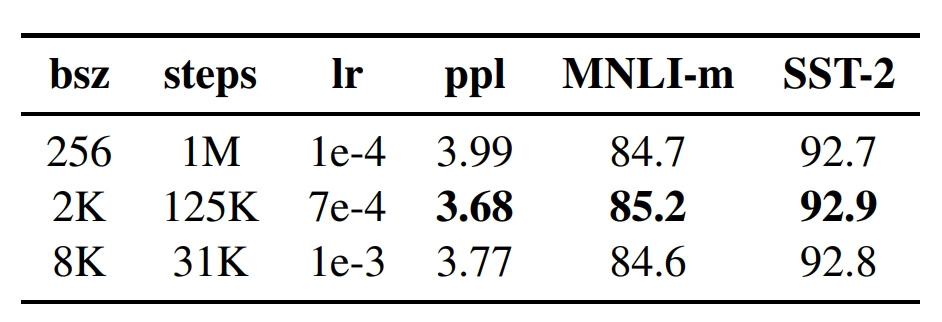
可以看出,增大batch_size能够改善MLM目标的困惑度和下游任务的准确率。除了 Batch-Size,还有训练步数,训练数据的量等。
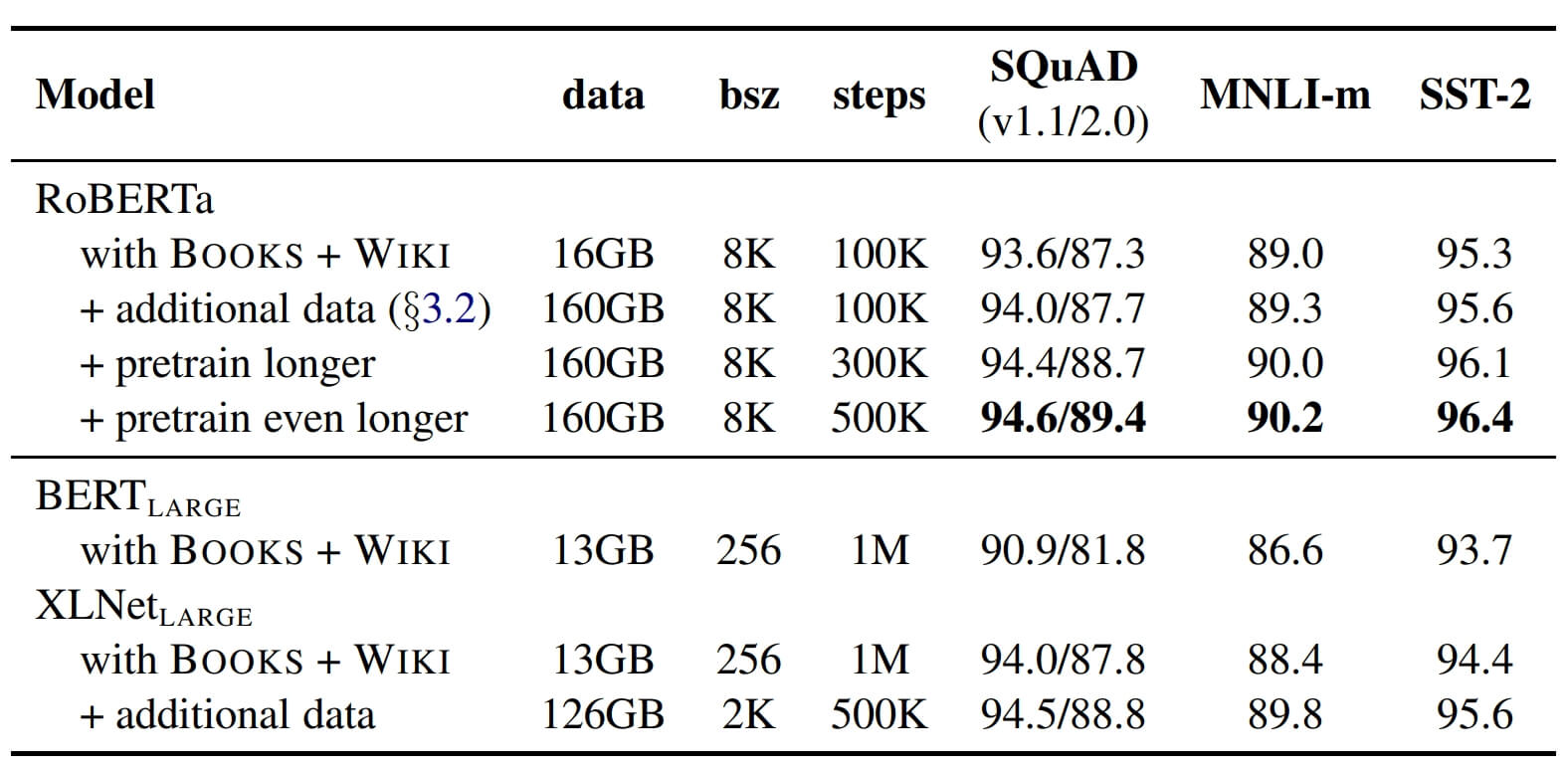
6. 总结
对于 RoBERTa 来说,通过拉长的训练时间、增加更多的数据、精细化的调参,能在 BERT 的基础上使得模型能力更上一层楼。
参考文献
[1] Liu Y, Ott M, Goyal N, et al. Roberta: A robustly optimized bert pretraining approach[J]. arXiv preprint arXiv:1907.11692, 2019.