1. 概述
Behavior Sequence Transformer(BST)算法是由阿里在2019年提出的算法,应用于淘宝推荐中的ranking阶段。在目前的推荐系统中,主流的深度学习方案,如WDL,并没有充分利用用户的行为序列(User’s Behavior Sequence),在BST算法中,利用Transformer充分挖掘用户的行为序列,实现对用户行为序列的建模。
2. 算法原理
BST算法的模型结构如下图所示:

在BST模型结构中,主要包括了三个部分:第一,特征的embedding层;第二,用户行为序列的Transformer层;第三,最终的MLP层。
2.1. Embedding层
Embedding层的结构如下所示:

从上图可以看出,在特征的Embedding层,主要包括三个部分:第一,其他的特征,主要包括用户画像特征,item特征,上下文特征以及交叉特征;第二,用户行为序列特征;第三,目标item的特征。
2.1.1. 其他特征
在其他特征部分,主要包括了用户画像特征,item特征,上下文特征以及交叉特征,具体特征形式在论文中也给出,如下所示:

将这些特征的embedding向量concat在一起,得到对应的embedding形式。
2.1.2. 用户行为序列和目标item
假设用户的行为序列为,同时还包括目标item 。对于每一个item(包括行为序列中的item以及目标item),包括两种类别的特征:第一,item的特征,如图中的红色部分;第二,位置特征,如图中的蓝色部分。对于item的特征,文章中指出使用的是item_id和category_id。为了使用Transformer刻画序列的特征,因此需要位置的特征,位置特征的计算方式为:
其中,表示item 被点击的时间戳。
将item特征和位置特征concat在一起,得到对应item的embedding表示。
2.2. Transformer层
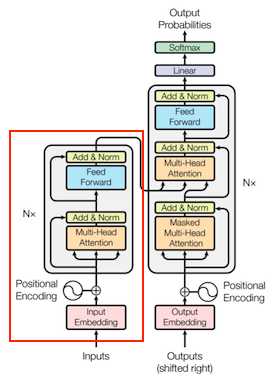
在Transformer层中使用Multi-Head Attention来学习目标item与用户行为序列中的item之间的相关关系。完整的Transformer指的是基于Attention机制的经典Encoder-Decoder框架,Transformer的框架结构如下图所示:
而在BST模型中,使用的是多个Multi-Head Attention结构,即Transformer的Encoding部分。Multi-Head Attention和Scaled Dot-Product Attention结构如下图所示:
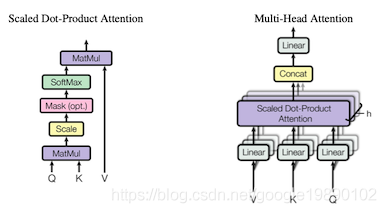
其中,Scaled Dot-Product Attention的值为:
其中,表示的是查询,和分别表示的是键和值,在BST中, ,,由用户行为序列和目标item的embedding的线性映射得到。
通过将Scaled Dot-Product Attention的结果concat在一起并通过线性变换得到最终的Multi-Head Attention结果:
其中,。除了上述的Multi-Head Attention部分,在Transformer的Encoding部分,还包括了Point-wise Feed-Forward Networks(FFN)部分,FFN的目的是增加模型的非线性。为了防止模型的过拟合,在self-attention和FFN中都使用dropout和LeakyReLU,最终的self-attention和FFN为:
通过堆叠多个上述的self-attention block,得到最终的多层结构,通过论文中的实验可知,只需要一层上述结构就能获得最好的结果,其可能的原因是用户行为序列间的依赖关系没有那么强。
2.3. MLP层以及损失函数
最终将其他特征的embedding以及Transformer的结果concat在一起,并通过三层的MLP得到最终的CTR预测。最终的损失函数为:
其中,表示样本个数,表示所有的样本,表示的是label,为模型的输出。
参考文献
[1] Chen Q , Zhao H , Li W , et al. Behavior Sequence Transformer for E-commerce Recommendation in Alibaba[J]. 2019.
[2] 阿里推荐算法(BST): 将Transformer用于淘宝电商推荐
[3] Vaswani A , Shazeer N , Parmar N , et al. Attention Is All You Need[J]. arXiv, 2017.