1. 概述
强化学习(Reinforcement Learning,RL)的概念相比较于监督学习或者非监督学习来说,对于初学者较难理解,其背后的原因是强化学习有着一套较为复杂的数学基础,要想理解这套数学基础就相对比较困难,而监督学习或者非监督学习的模型相比较而言,就显得简单的多,在这个系列中,我们以相对简单的语言来描述强化学习的基本知识,同时为不失专业性,我们也给出数学的推导,那就让我们开始吧。
首先我们来看一下强化学习的定义,较为正式的对强化学习的表述形式为:强化学习(Reinforcement Learning,RL)是一种通过与环境不断交互、试错来学习最优策略的机器学习方法,其数学基础框架是马尔可夫决策过程(Markov decision processes,MDP)。来了,从这个定义就已经对很多人劝退了,我们暂且先将把一些复杂的概念放在一边,以下面这个形象的画面开始。
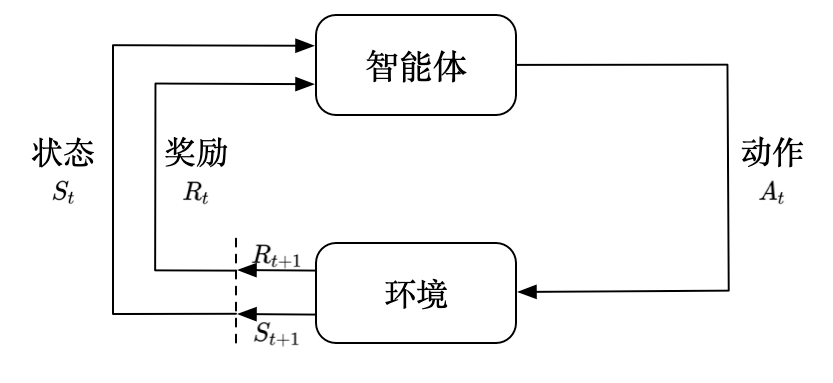
强化学习过程中有两个参与方:
- 一个是智能体(agent),也就是上图中的机器人;
- 另一个是环境(environment),也就是上图中的树木等自然环境。
有了参与方,那么在智能体和环境的交互过程中,就是出现对当前环境的描述,我们称之为状态(state);智能体根据当前的状态,决定下面应该如何做,这也就是动作(action),动作也不是无缘无故产生的,是根据当前的状态的,不妨假设动作是状态的一个映射,这个映射也有一个名字叫做策略(policy)。在智能体和环境的交互过程中也不能一直随便试错,需要沿着一个“获利”的路径,这就有了评价当前动作好坏的指标,称之为奖励(reward)。
除了上述的几个概念外,还有智能体与环境之间交互的总和,称为轨迹(trajectory),包含了(状态,动作)的集合。在单步上的奖励最大,并不能代表策略是最好的,只能说是在当前状态下的最好的动作,类似于局部最优,而强化学习的最终目标是要找到策略,使得在整个轨迹上能达到最好,我们把轨迹上的所有时间步的奖励总和称为回报(return)。
2. 数学描述
至此,强化学习的一部分重要概念已经介绍完成,也只能感性的认识到强化学习在做什么,理性地认识还是有必要的。下面我们将从数学概念对其进行表述。
2.1. 状态空间
状态是对某一时刻的环境的描述,所有的状态就构成了状态空间 S。在这里状态必须满足马尔可夫性(Markov Property),即下一时刻的状态只与当前的状态与行为相关,用数学表示就是:
P(st+1∣st,at)=P(st+1∣s0,a0,⋯,st,at)
2.2. 动作空间
动作是智能体在某个状态下执行的行为,如 at,所有的动作构成了动作空间 A,即 at∈A(st)。
2.3. 状态转移概率
当智能体在状态 st 下执行了动作 at 后,转移到下一个状态 st+1 的概率,称为状态转移概率 P(st+1∣st,at)。注意,在某些情况下,这个概率是已知的,而有些情况下是未知的。
2.4. 奖励(reward)
t 时刻的奖励是指智能体在 t 时刻,状态为 st 下,执行动作 at 后从环境 st+1 接收到的反馈:
Rt=r(st,at,st+1)
其中 r 为奖励函数(reward function),由 t 时刻的状态 st,t 时刻采取的动作 at 以及 t+1 时刻的状态 st+1 共同决定。
**注意:**这里有个奖励函数 r 以及 t 时刻的奖励 Rt 的概念有点难以理解。在这里重点阐述下,因为下面会使用到。
在强化学习中,当智能体在状态 st 下执行动作 at 时,环境会以一定的概率转移到下一个状态 st+1 ,并同时返回一个即时奖励 Rt 。这个奖励可能是固定的,也可能是一个随机变量。因此,通常可以用 P(st+1,Rt∣st,at) 来描述环境。
对于奖励函数,通常将其定义为即时奖励的条件期望:
r(s,a)=E[R∣s,a]=s′∑P(s′∣s,a)⋅R
这里的 r(s,a) 是一个确定性函数,告诉我们在状态 s 下执行动作 a 时,平均能获得多是即时奖励。
而对于即时奖励,如 Rt,时从上述分布中抽取的一个样本,如果环境是确定性的,那么 Rt 就等于 r(s,a),而如果环境是随机的,Rt 会围绕着 r(s,a) 波动。
2.5. 回报(return)
有了 t 时刻的奖励,回报 是指从当前时刻 t 开始,到未来结束为止,所有奖励的累积,通常会带上折扣:
Gt=Rt+γRt+1+γ2Rt+2+⋯=k=0∑∞γkRt+k
其中 γ 称为折扣因子,用于平衡当前奖励和未来奖励,当 γ=0 时,代表只关心当前收益,当 γ→1 时,代表更关注长期的收益。
综合上述的各个概念,由状态空间,动作空间,状态转移概率,奖励函数以及折扣因子共同定义了马尔可夫决策过程:
M=(S,A,P,R,γ)
如此,智能体便能与环境不断交互:
- 当前环境的状态 st
- 智能体根据一定的方法(后面会称为策略,暂时记为 π),选择出动作 at
- 根据状态转移概率,环境转移到 st+1∼P(⋅∣st,at)
- 智能体因此获得奖励 Rt
如此不断重复,便形成了轨迹。
2.6. 轨迹(trajectory)
轨迹是一系列状态和动作在时间上的序列:
τ=(s0,a0,s1,a1,⋯)
2.7. 策略(policy)
策略是从状态 st 到动作 at 的映射,决定了智能体从指定状态开始的行为方式,通常用 π 表示。策略 π 为:
π(at∣st)=P(at=a∣st=s)
策略又分为确定性策略和随机性策略,其中,确定性策略是指在每一个状态下只输出一个确定性的动作,即只有一个动作的概率为 1,其余都为 0。而随机性策略是指每一个状态下的输出是关于动作的概率。
除了上述的基本概念的数学表述外,还有两个非常重要的概念,分别为:状态价值函数和动作价值函数。
2.8. 状态价值函数
状态价值函数是在给定状态下,按照指定策略行动,未来获得的期望回报,即在 t 时刻,在状态 s 下,按照策略 π 行动,未来可以获得的期望回报:
Vπ(st)=Eτ∼π[Gt∣st=s]
简单解释下,状态价值函数衡量的是从某个状态开始(上述公式中是从状态 s 开始),遵循指定的策略(上述公式中的策略是 τ)带来的累积奖励(Gt)的期望,那么为什么是累积奖励的期望呢?因为即使每次从状态 s 出发,由于策略 τ 是随机的,导致采样到的轨迹并不是确定的。
2.9. 动作价值函数
动作价值函数,是在状态价值函数的基础上增加采取的动作。简单来说就是智能体在 t 时刻,在状态 s 下,先执行动作 a,再按照策略 π 行动,未来可以获得的期望回报:
Qπ(st,at)=Eτ∼π[Gt∣st=s,at=a]
那么问题来了,如何理解这两个价值函数?为什么需要两个价值函数呢?这两个价值函数之间是什么关系?我们应该如何使用这两个价值函数呢?
3. 强化学习算法的目标
有了上述的基本概念后,还有几个问题待回答,对于强化学习来说,最终需要做的是做决策,辅助决策的是评判这个决策好与不好的方法,当然最终是要选择一个好的决策。那么,决策就对应了策略,评判决策好与不好的方法就是回报的期望。强化学习要找到一个策略 π∗,使得总体回报的期望最高,策略就是讲的是在当前的状态下,是选择哪个动作,最终我们是需要反应到动作上的,指导在当前的状态下,该如何进行下一步。而在上述的状态价值函数和动作价值函数中,动作价值函数正好包含了动作,自然地,最优的策略即是在每个状态下选择出回报最大动作的方法,即:
π∗(s)=aargmaxQ∗(s,a)
用通俗的理解,Vπ(s) 是状态 s 下的好不好,而 Qπ(s,a) 是在状态 s 下执行动作 a 的好不好,两者之间的关系为:
Vπ(s)=a∑π(a∣s)Qπ(s,a)
因此在最优情况下:
V∗(s)=amaxQ∗(s,a)
总结一下:
- Vπ(s) 是状态 s 下的好不好,而 Qπ(s,a) 是在状态 s 下执行动作 a 的好不好
- 两者之间是有等价的
- 等价关系为:Vπ(s)=∑aπ(a∣s)Qπ(s,a)
- 在强化学习中的目标使用的是动作价值函数 Qπ(s,a)
4. 贝尔曼方程(Bellman Equations)
上面描述了在这个过程中就是在找能使得回报的期望最大的决策,那么有什么办法能够求的当前状态的回报的期望呢?这里就要用到贝尔曼方程,贝尔曼方程也是强化学习中非常非常重要的理论基础。用一句话来概括贝尔曼方程就是:
当前状态的价值=当前的奖励+未来最优回报的期望
如何理解这个过程,举个简单的例子,假设每天的选择就是学习和玩:
- 学习,短期痛苦(当前奖励少),长期收益高
- 玩,短期快乐(当前奖励多),长期收益低
那么,当前状态的回报应该是两部分相加。这正是贝尔曼方程所要表达的意思。
4.1. 贝尔曼期望方程
4.1.1. 动作价值函数
先看看动作价值函数 Qπ(s,a),则有:
Qπ(s,a)=Eτ∼π[Gt∣st=s,at=a]=Eτ∼π[Rt+γRt+1+⋯∣st=s,at=a]=Eτ∼π[Rt+γ(Rt+1+γrt+2+⋯)∣st=s,at=a]=Eτ∼π[Rt+γGt+1∣st=s,at=a]=Eτ∼π[Rt∣st=s,at=a]+γEτ∼π[Gt+1∣st=s,at=a]
而对于 Eτ∼π[Gt+1∣st=s,at=a],则有:
Eτ∼π[Gt+1∣st=s,at=a]=Eτ∼π[Eτ∼π[Gt+1∣st+1=s′,at+1=a′]∣st=s,at=a]=Eτ∼π[Qπ(s′,a′)∣st=s,at=a]
因此有:
Qπ(s,a)=Eτ∼π[Rt+γQπ(s′,a′)∣st=s,at=a]
根据上面对于奖励的理解:奖励函数可以定义为奖励即时奖励的期望,即,
r(s,a)=E[R∣s,a]=s′∑P(s′∣s,a)⋅R
同时,对条件概率的期望展开,因此,上面的动作价值函数可以写成:
Qπ(s,a)=r(s,a)+γs′∑P(s′∣s,a)a′∑π(a′∣s′)Qπ(s′,a′)
4.1.2. 状态价值函数
对于状态价值函数,展开可得:
Vπ(st)=Eτ∼π[Rt+γVπ(st+1)∣st=s]
表述就是:一个状态的价值,等于在该状态下,按照策略行动时,一步即时收益 + 折扣后的未来价值的期望。如何得到这个公式呢?需要对状态价值函数展开:
Vπ(st)=Eτ∼π[Gt∣st=s]=Eτ∼π[Rt+γRt+1+⋯∣st=s]=Eτ∼π[Rt+γ(Rt+1+γRt+2+⋯)∣st=s]=Eτ∼π[Rt+γGt+1∣st=s]
而对于第二项 Eτ∼π[γGt+1∣st=s] ,可以做如下的转换:
Eτ∼π[γGt+1∣st=s]=γEτ∼π[Eτ∼π[Gt+1∣st+1=s′]∣st=s]=γEτ∼π[Vπ(st+1)∣st=s]
最终,有:
Vπ(st)=Eτ∼π[Rt+γVπ(st+1)∣st=s]
根据状态价值函数与动作价值函数之间的关系,即:Vπ(s)=∑aπ(a∣s)Qπ(s,a),则有:
Vπ(s)=a∑π(a∣s)Qπ(s,a)=a∑π(a∣s)(r(s,a)+γs′∑P(s′∣s,a)a′∑π(a′∣s′)Qπ(s′,a′))=a∑π(a∣s)(r(s,a)+γs′∑P(s′∣s,a)Vπ(s′))
4.2. 贝尔曼最优方程
至此,我们推到出了动作价值函数的贝尔曼期望方程形式和状态价值函数的贝尔曼期望方程形式,根据 V∗(s) 和 Q∗(s,a) 能够得到贝尔曼最有方程:
V∗(s)=amax{r(s,a)+γs′∑P(s′∣s,a)V∗(s′)}
Q∗(s,a)=r(s,a)+γs′∑P(s′∣s,a)a′maxQ∗(s′,a′)
5. 强化学习的分类
有了上述的分析,接下来就要进入到具体的求解过程了,在各种强化算法中,可以根据不同的标准将算法分成不同的类别。
5.1. model-based 与 model-free
model-based 与 model-free 是强化学习中最基本的分类,这里的模型 model 指的是环境模型,环境模型主要指的是状态转移概率 P(st+1∣st,at),根据状态转移矩阵是否可知,分为 model-based 和 model-free 两种,主流的一些方法,如 DQN,PPO 等都属于 model-free 的方法。
5.2. on-policy 与 off-policy
on-policy 与 off-policy 指的是智能体与环境交互过程中采集数据使用的模型与学习更新的策略是否一致,如果一致,则为 on-policy,否则为 off-policy。常见的 on-policy 的算法有 REINFORCE,PPO 等,常见的 off-policy 的算法有 Q-learning 等。
5.3. value-based 与 policy-based
这种分类方式是基于智能体学习的目标来分的,也是最重要的一种分类方式,因为强化学习的目标是使得总体回报的期望最高,那么直接可以对价值建模,也可以对策略建模,因此就存在 value-based 和 policy-based 两种不同的方法。常见的 value-based 的算法有 Q-learning 等,常见的 policy-based 的算法有 REINFORCE 等,同时,还有结合了两者的 Actor-Critic 方法,当前主流的方法都是基于 Actor-Critic 的方法。
参考文献
[1] https://datawhalechina.github.io/easy-rl