1. value-based
我们知道,在强化学习中,学习的目标是要找到一个策略 ,使得总体回报的期望最高。这里的回报就是状态价值函数 和动作价值函数 。而基于值的方法并不直接对策略 建模,而是先学习并优化价值函数,然后基于价值函数来推导出最优策略:
以上便是 value-based 强化学习的核心思想。
接下来的问题就是如何估计出动作价值函数。基于值的方法主要有三大类,分别为:动态规划、蒙特卡洛方法和时序差分算法。本篇中介绍的是动态规划的方法。
2. 动态规划
动态规划(dynamic programming)是程序设计中非常重要的一部分,能够高效地解决很多的一些经典问题。其核心思想是将待求解的问题分解成若干个子问题,通过对子问题的求解,从而得到最终目标问题的求解。那么关键就是基于价值的强化学习目标函数是否可以拆解成若干个子问题?答案是“可以”。
2.1. 强化学习基本思路
在上面介绍到强化学习的目标,在达成目标的过程中,通常是沿袭着两个步骤:
- 评估策略的价值,也就是对当前策略的一个评判,评判的方式有状态价值函数 和动作价值函数
- 改进策略,当有了更高的价值时,就需要改进当前的策略
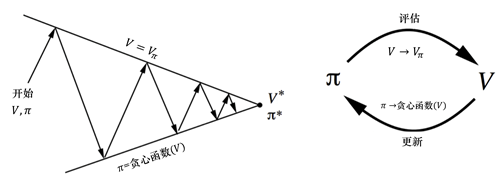
上述两个过程不断地循环往复,评估->改进->再评估->再改进->…,直到最终的收敛,就能得到价值最高的策略。上述两个过程分别有对应的名称,分别为:策略评估、策略提升[1]。
2.2. 动态规划
动态规划的核心思想是将待求解的问题分解成若干个子问题,通过对子问题的求解,从而得到最终目标问题的求解。对于价值函数,有贝尔曼最优方程,状态价值函数的贝尔曼最优方程为:
动作价值函数的贝尔曼最优方程为:
因为 ,对动作价值函数做简单的调整:
通过上式,我们便找到了这样的子问题,即 和 之间的关系。
但是从另一个角度上来看,要想实现上述的迭代过程,就必须知道环境,即状态转移概率 和奖励函数 。在动态规划中还有两种不同的方法,分别为策略迭代和价值迭代。
2.3. 策略迭代
策略迭代严格按照上述“评估->改进->再评估->再改进->…”这样的路线:
- 策略评估,即评估一个策略的价值,理论上这里既可以选择状态价值函 ,也可以选择动作价值函数 (原因是 和 之间存在对应的转换关系),标准的做法是选择状态价值函数
- 策略改进,可以使用贪心策略,选择价值最大的策略:
我们注意到上述的策略评估和策略改进之间存在着将 转换成 的过程,其转换公式为:
这个转换过程中用到了贝尔曼期望方程中的动作价值函数的形式:
这个公式是如何得到的,首先,根据 ,上式可以写成:
再将求和提到最外面,便得到:
接下来,我们选择 Frozen Lake[2] 问题展开实验,实验的环境如下:
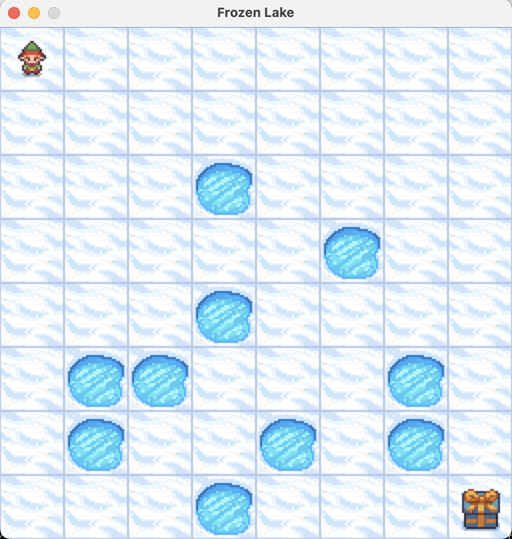
从左上角走到右下角,不能走到冰洞中,更对的背景可以参照参考文献 2。构建 DynamicPrograming 类,写出 __policy_iteration 策略迭代的代码,如下:
import numpy as np
import gymnasium as gym
class DynamicPrograming:
def __init__(self, env):
self.env = env # 环境
self.state_size = env.observation_space.n # 状态空间大小
self.action_size = env.action_space.n # 动作空间大小
self.q_table = np.random.uniform(low=0, high=0.01, size=(self.state_size, self.action_size)) # Q-table
def __policy_iteration(self, gamma=0.99):
''' 策略迭代
'''
theta = 1e-8
# INFO: 初始化策略
policy = np.zeros(self.state_size, dtype=int)
value = np.zeros(self.state_size)
iteration = 0
while True:
delta = 0 # 终止条件
iteration += 1
print(f"iter: {iteration}")
# INFO: 策略评估
while True:
delta = 0
# INFO: 对每一个状态计算状态价值函数
for s in range(self.state_size):
v = value[s] # 获取当前的状态价值
a = policy[s] # 获取当前状态下的策略
# INFO: 取下一步完整的概率
new_v = 0
for prob, next_state, reward, terminated in self.env.unwrapped.P[s][a]:
new_v += prob * (reward + gamma * value[next_state])
value[s] = new_v
delta = max(delta, abs(v - value[s]))
# INFO: 终止
if delta < theta:
break
# INFO: 策略更新
policy_stable = True
for s in range(self.state_size):
old_action = policy[s] # 获取当前的策略
# INFO: 计算当前状态下的 Q-table
q_table_s = np.zeros(self.action_size)
for a in range(self.action_size):
for prob, next_state, reward, terminated in env.unwrapped.P[s][a]:
q_table_s[a] += prob * (reward + gamma * value[next_state])
best_action = np.argmax(q_table_s) # INFO: 贪心取最优策略
policy[s] = best_action
# INFO: 记录到 Q-table 中
for a in range(self.action_size):
self.q_table[s][a] = q_table_s[a]
# INFO: 判断是否收敛
if old_action != best_action:
policy_stable = False
if policy_stable:
print(f"Policy Iteration Converged in {iteration} iterations")
break
return self.q_table
同时,在类中实现统一的外部调用函数 train,代码如下:
def train(self, is_policy_iterater=True):
if is_policy_iterater:
return self.__policy_iteration()
最后,补全完整的实验调用:
if __name__ == "__main__":
# INFO: 创建环境
env = gym.make('FrozenLake-v1', map_name="8x8", is_slippery=False)
dp = DynamicPrograming(env)
q_table = dp.train()
env.close()
# INFO: 测试
env_test = gym.make('FrozenLake-v1', map_name="8x8", is_slippery=False, render_mode='human')
print("测试环境初始化完成")
state, _ = env_test.reset()
done = False
step = 0
while not done:
action = np.argmax(q_table[state, :])
state, reward, terminated, truncated, _ = env_test.step(action)
done = terminated or truncated
print(f"step={step}, action={action}, state={state}, reward={reward}")
step += 1
print("Test finished.")
env_test.close()
我们来看一下最终的实验结果:
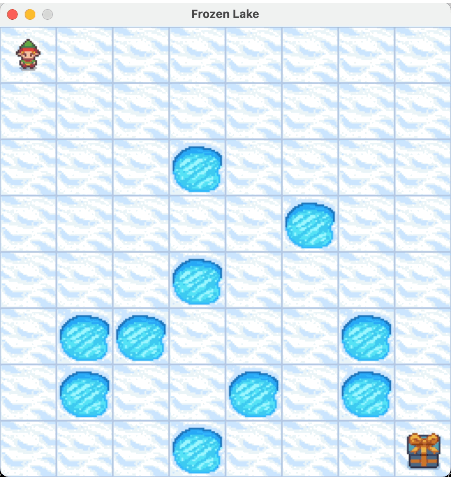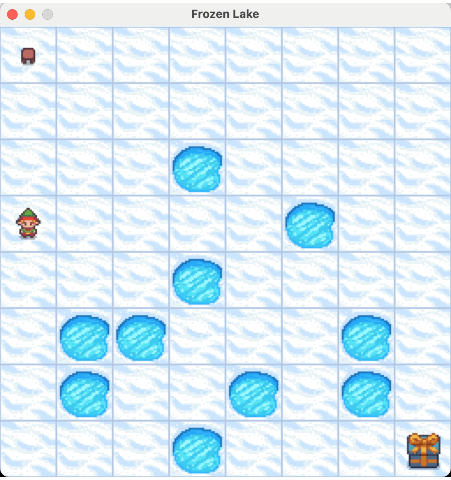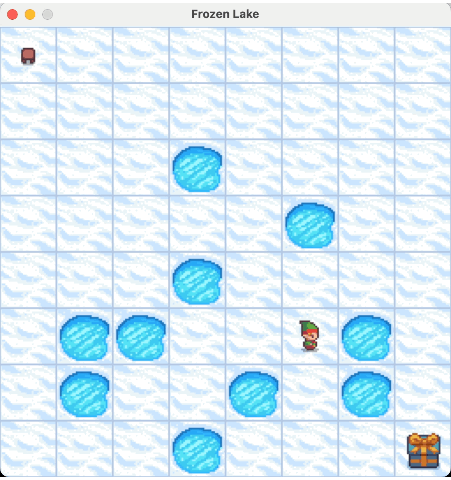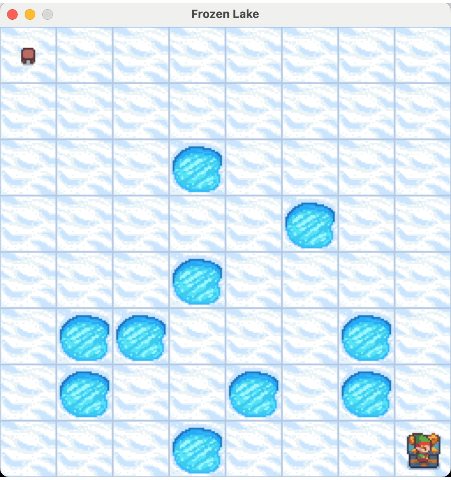
2.4. 价值迭代
在价值迭代中,使用的是贝尔曼最优方程的状态价值函数的形式:
同样,将求和移动到最外面,得到:
其在每次更新状态价值函数 时,都假设的是使用最优策略,使得每一步的状态价值函数都是所有行为中最好的。直接修改上面的代码,增加价值迭代函数 __value_iteration 部分:
def __value_iteration(self, gamma=0.99):
""" 价值迭代
"""
theta = 1e-8
iteration = 0
value = np.zeros(self.state_size)
while True:
delta = 0
iteration += 1
print(f"iter: {iteration}")
for s in range(self.state_size):
v = value[s]
# INFO: 计算当前状态下的 Q-table
q_table_s = np.zeros(self.action_size)
for a in range(self.action_size):
for prob, next_state, reward, terminated in env.unwrapped.P[s][a]:
q_table_s[a] += prob * (reward + gamma * value[next_state])
value[s] = np.max(q_table_s) # 核心的不同,每一个状态下都选最优
delta = max(delta, abs(v - value[s]))
# INFO: 记录到 Q-table 中
for a in range(self.action_size):
self.q_table[s][a] = q_table_s[a]
if delta < theta:
print(f"Value Iteration Converged in {iteration} iterations")
break
return self.q_table
同时,补全 train 函数:
def train(self, is_policy_iterater=True):
if is_policy_iterater:
return self.__policy_iteration()
else:
return self.__value_iteration()
至此,基于动态规划的方案介绍完成。
参考文献
[1] https://datawhalechina.github.io/easy-rl/#/chapter3/chapter3?id=_31-马尔可夫决策过程
[2] https://gymnasium.farama.org/environments/toy_text/frozen_lake/