1. value-based
在强化学习中,学习的目标是要找到一个策略 ,使得总体回报的期望最高。这里的回报就是状态价值函数 和动作价值函数 。而基于值的方法并不直接对策略 建模,而是先学习并优化价值函数,然后基于价值函数来推导出最优策略:
以上便是 value-based 强化学习的核心思想。
基于值的方法主要有三大类,分别为:动态规划、蒙特卡洛方法和时序差分算法。在动态规划中,需要事先知道转移矩阵 和奖励函数 ,这两个参数就构成了模型,因此动态规划也划分到基于模型(model-based)方法。
在蒙特卡洛方法中,虽不需要事先知道模型,但是更新需要得到当前的采样结束后,才能对动作价值函数 更新,更新较慢,同时,蒙特卡洛方法的高方差也导致了整体的训练会出现不平稳的现象。在蒙特卡洛方法中,其更新公式为:
基于时序差分算法对上述的问题进行了优化,典型的算法如 Sarsa 算法。在 Sarsa 算法中,由于其基于时序差分算法,能充分利用每一步来更新动作价值函数,其更新公式为:
由于每一步的更新都依赖当前的策略 ,故 Sarsa 算法也被称之为 on-policy 的算法。
在 Sarsa 算法中,其学习的目标是在策略 下的动作价值函数 ,这是一个与当前策略 相关的目标,在策略评估和策略更新时都是基于策略 ,而在 Q-Learning 算法中,其学习的目标是最优的动作价值函数 ,其更新公式为:
这个目标与策略无关,策略的评估和策略的更新不是同一个策略,因此 Q-Learning 算法也被称为 off-policy 算法。
但是,我们发现,在 Q-Learning 的实现过程中,包括以上的算法中,都需要维护一个动作价值函数的 Q-Table,其中,行表示的是状态,列表示的是动作,交叉处记录的是 Q 值。这样的一种环境,只能处理离散的问题,同时状态空间,动作空间都比较小的环境,然而现实世界中还存在着大量的连续型的环境。在这样的环境下,用表格存储所有状态是不现实的。
那么,能否用一个函数 来表示在状态 下采取行动 的动作状态价值, 表示的是函数的参数?答案是“可以”。这便是 Deep Q-Network[1],简称 DQN。DQN 是由 DeepMind 在 2013 年提出,采用神经网络对函数 建模。
2. Deep Q-Network
2.1. 存在问题
上面已经提及用神经网络对函数 建模,从而解决传统基于 Q-Table 这种只能处理离散状态的问题。但是直接将 Q-Learning 与非线性神经网络结合是极不稳定的,这个一部分原因是采集到的轨迹数据之间存在着相关性,但是神经网络建模时要求样本必须独立同分布;另一部分原因是在 Q-Learning 的更新公式 依赖于当前正在训练的网络。
为此,在 DQN 中必须要解决上述说的两个问题,因此有如下的改进:
- 经验回放:将轨迹拆分成每一条经验 ,并将其存到一个回放缓存中,当需要的时候,通过采样,随机抽取一批数据,以此来打破经验之间的相关性;
- 创建两个 Q 值网络,分别为策略网络 和目标网络 ,策略网络负责选择动作,并不断更新,而目标网络负责计算 Q 值,参数 并不是像策略网络那样每次都更新,而是每隔一定步数才更新一次。这样能给网络提供一个稳定的训练目标,一定程度上抑制了震荡和发散。
2.2. DQN 算法
2.2.1. 目标函数
再次回顾下,在 Q-Learning 算法中,我们已知:
我们需要学习到的目标网络可以表述为:
2.2.2. 损失函数
损失函数可以选择 MSE 或者 SmoothL1,其中 MSE 为:
SmoothL1 为:
其中 。
2.2.3. 算法流程
完整的算法流程为:
- Step 1:初始化,包括策略网络 ,目标网络 ,回放缓存
- Step 2:按照 episode 循环
- Step 2.1:与环境交互,选择动作
- Step 2.2:存储经验:
- Step 2.3:采样训练:从回放缓存中随机采样 batch 大小的样本
- Step 2.4:计算目标值:
- Step 2.5:更新网络:根据损失函数优化策略网络
- Step 2.6:更新目标网络:按照一定步数更新目标网络
- Step 3:训练结束,保存出模型
2.3. 算法实现
这一次,我们采用的环境是 Cart Pole[2],这是一个连续状态的问题。该问题的动作空间中的动作有两个,状态是由 4 个值确定的,分别为 Cart Position,Cart Velocity,Pole Angle 和 Pole Angular Velocity。更多详细情况如参考文献 2。代码部分参考了 Pytorch 中关于 DQN 的教程[3]。
2.3.1. 构建网络
首先,需要创建一个网络,包括策略网络和目标网络(实际上这两个网络结构是同样的),以最简单的三层 DNN 网络为例,构建 DQN 类:
# INFO: 构建 DQN 网络
class DQN(nn.Module):
def __init__(self, n_observations, n_actions):
super(DQN, self).__init__()
self.layer1 = nn.Linear(n_observations, 128)
self.layer2 = nn.Linear(128, 128)
self.layer3 = nn.Linear(128, n_actions)
def forward(self, x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
return self.layer3(x)
2.3.2. 回放缓存
有了 DQN 网络结构,还需要一个存放采样样本的缓存,这里构建一个 ReplayMemory 的类,里面包含了 push()、sample()、len() 方法,从名字也很容易猜到每个函数的含义,分别为插入样本、采样样本、缓存大小。
# INFO: 用于经验回放的记忆库
class ReplayMemory:
def __init__(self, capacity):
self.memory = deque([], maxlen=capacity)
def push(self, transition_tuple):
self.memory.append(transition_tuple)
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def len(self):
return len(self.memory)
2.3.3. 训练
有了以上的结构的准备,接下来就是要按照上述的训练流程,实施“采样->存储到缓存->从缓存采样->模型训练->更新”这样的循环,直接上代码,这里代码参考了文献 3 中的代码:
class DQNAgent:
def __init__(self, env, device):
self.env = env
self.device = device
self.n_actions = env.action_space.n
self.n_observations = env.observation_space.shape[0] # 连续空间
# INFO: 定义策略网络和目标网络,并在初始时,让两个网络参数相同
self.policy_net = DQN(self.n_observations, self.n_actions).to(self.device)
self.target_net = DQN(self.n_observations, self.n_actions).to(self.device)
self.target_net.load_state_dict(self.policy_net.state_dict())
# INFO: 定义优化器
self.lr = 3e-4 # 学习率
self.optimizer = optim.AdamW(self.policy_net.parameters(), lr=self.lr, amsgrad=True)
# INFO: 初始化用于经验回放的记忆库
self.memory = ReplayMemory(10000)
# INFO: 其他的参数
self.num_episodes = 600
self.batch_size = 128
self.gamma = 0.99
self.eps_start = 0.9
self.eps_end = 0.01
self.eps_decay = 2500
self.tau = 0.005
self.step_done = 0
def __optimize_model(self):
# INFO: 没有足够的样本直接退出
if self.memory.len() < self.batch_size:
return 2 # 返回一个较大的数
# INFO: 采样
batch_transitions = self.memory.sample(self.batch_size)
non_final_mask = torch.tensor(tuple(map(lambda s: s[2] is not None, batch_transitions)), device=self.device, dtype=torch.bool)
non_final_next_states = torch.cat([s[2] for s in batch_transitions if s[2] is not None])
state_batch = torch.cat([transition[0] for transition in batch_transitions])
action_batch = torch.cat([transition[1] for transition in batch_transitions])
reward_batch = torch.cat([transition[3] for transition in batch_transitions])
# INFO: 预测 Q
state_action_values = self.policy_net(state_batch).gather(1, action_batch)
next_state_values = torch.zeros(self.batch_size, device=self.device)
with torch.no_grad():
next_state_values[non_final_mask] = self.target_net(non_final_next_states).max(1).values
expected_state_action_values = (next_state_values * self.gamma) + reward_batch
criterion = nn.SmoothL1Loss()
loss = criterion(state_action_values, expected_state_action_values.unsqueeze(1))
ret_loss = loss.item()
self.optimizer.zero_grad()
loss.backward()
# In-place gradient clipping
torch.nn.utils.clip_grad_value_(self.policy_net.parameters(), 100)
self.optimizer.step()
return ret_loss
def train(self):
train_reward_list = []
train_loss = []
for episode in range(self.num_episodes):
print(f"episode: {episode}")
# INFO: 重置环境
state, info = self.env.reset()
state = torch.tensor(state, dtype=torch.float32, device=self.device).unsqueeze(0)
episode_reward = 0.0
while True:
# INFO: 选择行动
sample = random.random()
eps_threshold = self.eps_end + (self.eps_start-self.eps_end) * math.exp(-1. * self.step_done / self.eps_decay)
self.step_done += 1
action = torch.tensor([[self.env.action_space.sample()]], device=self.device, dtype=torch.long)
if sample > eps_threshold:
with torch.no_grad():
action = self.policy_net(state).max(1).indices.view(1,1)
# INFO: 进入下一个状态
observation, reward, terminated, truncated, _ = self.env.step(action.item())
episode_reward += reward # 更新 episode_reward
reward = torch.tensor([reward], device=self.device)
done = terminated or truncated
if terminated:
next_state = None
else:
next_state = torch.tensor(observation, dtype=torch.float32, device=self.device).unsqueeze(0)
# INFO: 将记录存储到记忆库中
self.memory.push((state, action, next_state, reward))
state = next_state
# INFO: 优化模型
ret_loss = self.__optimize_model()
train_loss.append(ret_loss)
# INFO: 更新模型
for target_param, policy_param in zip(self.target_net.parameters(), self.policy_net.parameters()):
target_param.data.copy_(self.tau * policy_param.data + (1 - self.tau) * target_param.data)
if done:
break
train_reward_list.append(episode_reward)
# INFO: 最终保存出模型
torch.save(self.target_net.state_dict(), 'dqn_cartpole.pth')
# INFO: 保存最终的训练状态
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4)) # 1行2列,图形尺寸可调
ax1.plot(train_reward_list)
ax1.set_xlabel("episode")
ax1.set_ylabel('reward')
ax1.set_title('Reward')
ax2.plot(train_loss)
ax2.set_xlabel("epoch")
ax2.set_ylabel('loss')
ax2.set_title('loss')
plt.tight_layout()
plt.savefig("reward_loss.png")
上述代码对文献 3 中的代码做了较大的改动。里面涉及到一些训练的策略,这个会在后面提到。
有了完整的过程,启动训练:
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else"cpu")
env = gym.make("CartPole-v1")
dqn_agent = DQNAgent(env, device=device)
dqn_agent.train()
env.close()
2.3.4. 结果与测试
经过简单的训练,最终保存出名为 dqn_cartpole.pth 目标网络的模型,同时我们可以看到训练过程中的数据表现:
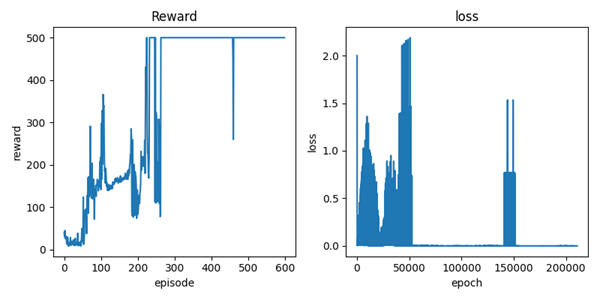
再写一段测试的脚本,用于测试模型的表现,如下:
if __name__ == "__main__":
mode = "test"
device = torch.device("cuda" if torch.cuda.is_available() else"cpu")
if mode == "train":
env = gym.make("CartPole-v1")
dqn_agent = DQNAgent(env, device=device)
dqn_agent.train()
env.close()
else:
# INFO: 测试
test_env = gym.make("CartPole-v1", render_mode='human')
n_actions = test_env.action_space.n
n_observations = test_env.observation_space.shape[0] # 连续空间
# INFO: 定义模型
target_net = DQN(n_observations, n_actions).to(device)
# 2. 加载状态字典
state_dict = torch.load('dqn_cartpole.pth', map_location=torch.device('cpu')) # 或 'cuda'
# 3. 将参数加载到模型中
target_net.load_state_dict(state_dict)
# 4. 设置为评估模式(如果只做推理)
target_net.eval()
num_episodes = 10
for ep in range(num_episodes):
state, _ = test_env.reset()
done = False
total_reward = 0
while not done:
test_env.render()
state = torch.tensor(state, dtype=torch.float32, device=device)
action = target_net(state).max(0).indices.view(1, 1)
next_state, reward, terminated, truncated, _ = test_env.step(action.item())
done = terminated or truncated
total_reward += reward
if done:
print(f"terminated: {terminated}, truncated: {truncated}")
break
state = next_state
print(f"Test Episode {ep+1}: Total Reward = {total_reward}")
test_env.close()
最终的表现如下:

注:每一个 episode 都是执行到 Reward = 500.0 时就 truncated 了。
2.4. 实现中的一些技巧
2.4.1. 模型的更新
在 DQN 中,有结构相同的两个网络,分别为策略网络 policy_net 和目标网络 target_net,其目的是稳定训练。target_net 的参数不是始终等于 policy_net 的参数,而是定期或平滑地同步。实现方式主要有两种:硬更新(Hard Update) 和 软更新(Soft Update)。其中硬更新是每隔固定的步数直接将 policy_net 的当前参数复制给 target_net。而在上述代码中使用的是软更新,也就是每一步都缓慢地将 policy_net 的参数混合进 target_net,公式为:
其中 是一个很小的超参数,代码为:
# INFO: 更新模型
for target_param, policy_param in zip(self.target_net.parameters(), self.policy_net.parameters()):
target_param.data.copy_(self.tau * policy_param.data + (1 - self.tau) * target_param.data)
2.4.2. 梯度的值裁剪
在代码中有如下一段代码:
torch.nn.utils.clip_grad_value_(self.policy_net.parameters(), 100)
其中 torch.nn.utils.clip_grad_value_ 是 PyTorch 提供的梯度裁剪函数,直接修改参数的 .grad 属性,将每个梯度值限制在 区间内。主要的目的是防止梯度爆炸,以稳定训练。
3. 总结
通过神经网络对函数 建模,从而解决传统基于 Q-Table 这种只能处理离散状态的问题,同时通过经验回放,缓慢更新等策略,确保在 DQN 中训练的稳定性。
参考文献
[1] Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning[J]. arXiv preprint arXiv:1312.5602, 2013.
[2] https://gymnasium.farama.org/environments/classic_control/cart_pole/
[3] https://docs.pytorch.org/tutorials/intermediate/reinforcement_q_learning.html