Label Stuido 是一个较成熟的标注系统,平时在做 CV 相关的业务时,会使用 Label Stuido 进行训练数据的标注。当然,除了对原始数据的标注之外,还有一部分的需求是对预测后的结果进行“微标注”,也就是对预测的结果做细微调整。然后就是这第二部分的工作,在 Label Studio 中支持得并不是很友好。我从我个人的实践中总结出一套非常好的方式供大家参考,主要针对于图像分割场景,其他场景类似。
1. 安装与标注
首先需要安装 Label Studio,参考 Github[1],这里采用 pip 在本地安装,直接根据脚本:
pip install label-studio
安装完成后执行启动命令:
label-studio
注意:要找到 label-studio 的具体位置,例如“./Library/Python/3.9/bin/label-studio”
启动完成后,就可以进入到 Label Studio 的界面,如下:

后面就进入创建流程,导入数据,选择对应的标注类型。这里就不再展示。标注完成后,选择导出数据(选择对应的导出类型),就可以导出数据用于接下来的训练了。
以上便是一个完整的数据标注以及导出的流程,模型训练完成后,一般需要经过多轮的调整,模型才能达到理想的效果,那么 Label Studio 中如何支持已标注的结果?
2. 微调模型的标注结果
2.1. 导入图片
沿着创建,导入的流程导入图片,如下:
导入完成后在 Settings 页面设置好标注类型,如本例中的图像分割,code 如下:
<View>
<Header value="Select label and click the image to start"/>
<Image name="image" value="$image" zoom="true"/>
<PolygonLabels name="label" toName="image" strokeWidth="3" pointSize="small" opacity="0.9">
<Label value="gear" background="red"/>
</PolygonLabels>
</View>
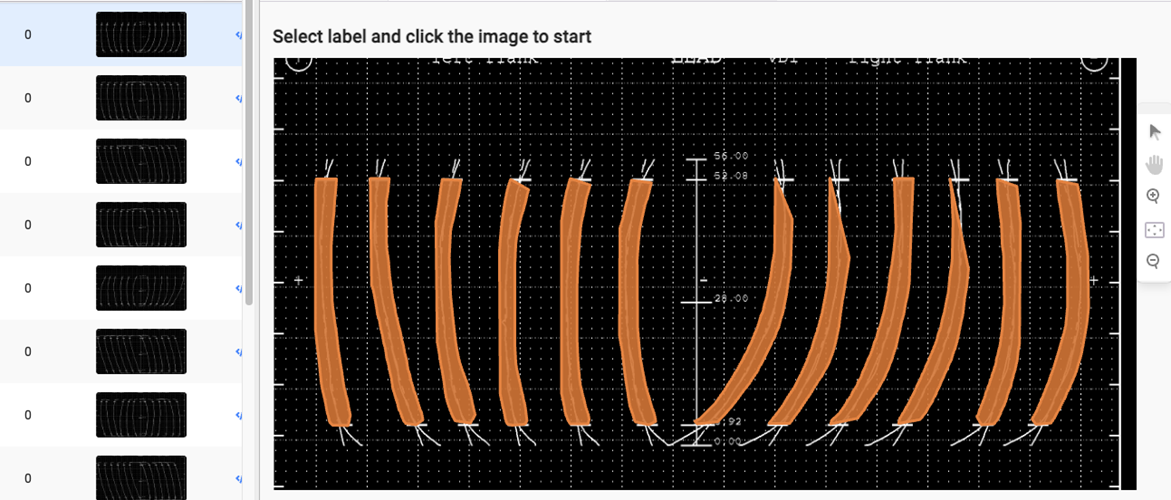
得到界面如下:
此时,注意到图片存储的位置:

关键的一步:找到导入图片在本地的位置,一般在 label-stuido 下面的 media/upload 文件夹下
2.2. 模型预测
假设已训练好一个图像分割模型,对刚刚导出的数据预测,并生成一份数据,以 YOLO 为例,生成文件的代码如下:
def save_yolo_seg_format(results, img_path, output_label_dir):
"""
将推理结果保存为 YOLO 分割训练格式的 .txt 文件
每行: class_id x1 y1 x2 y2 ... xn yn (归一化坐标)
"""
os.makedirs(output_label_dir, exist_ok=True)
base_name = os.path.splitext(os.path.basename(img_path))[0]
txt_path = os.path.join(output_label_dir, f"{base_name}.txt")
with open(txt_path, 'w') as f:
for result in results:
if result.masks is None:
continue
if result.boxes is None or len(result.boxes.cls) == 0:
continue
for i, mask in enumerate(result.masks):
# 将多边形点转换为 numpy 数组并展平为一维
poly = np.array(mask.xyn)
coords = poly.flatten().tolist() # 展平为 [x1,y1,x2,y2,...]
cls_id = int(result.boxes.cls[i].item())
line = f"{cls_id} " + " ".join(f"{c:.6f}" for c in coords)
f.write(line + "\n")
print(f"Saved segmentation labels to {txt_path}")
保存出来的数据如下图所示:

此时,需要将数据导入到 Label Studio 中。
2.3. 准备标注结果
用下面的脚本将图像的标注结果转换成 Label Studio 要求的格式,代码如下:
import os
import json
from PIL import Image
IMAGE_DIR = "/Users/felix.zhao2/Library/Application Support/label-studio/media/upload/125/"
# 读取所有的图片的文件名
file_list = []
for filename in os.listdir(IMAGE_DIR):
file_list.append(filename.strip())
# 配置
LABEL_DIR = "labels"
OUTPUT_JSON = "labelstudio_import.json"
LABEL_PATH = "/data/upload/122/"
CLASS_MAP = {
0: "object"
}
# Label Studio 配置里的名字
FROM_NAME = "label"
TO_NAME = "image"
# 转换
tasks = []
for txt_name in os.listdir(LABEL_DIR):
if not txt_name.endswith(".txt"):
continue
txt_path = os.path.join(LABEL_DIR, txt_name)
base_name = os.path.splitext(txt_name)[0]
image_path = None
image_ext_found = ""
for ext in [".jpg", ".jpeg", ".png", ".bmp"]:
p = os.path.join(IMAGE_DIR, base_name + ext)
if os.path.exists(p):
image_path = p
image_ext_found = ext
break
if image_path is None:
print(f"找不到图片: {base_name}")
continue
# 获取图片尺寸,用于将归一化坐标转换为百分比
img = Image.open(image_path)
width, height = img.size
img.close() # 读取后及时关闭文件
# 正确匹配 file_list 中的文件名
image_full_name = base_name + image_ext_found
ls_image_path = ""
for all_name in file_list:
if image_full_name in all_name:
ls_image_path = f"{LABEL_PATH}{all_name}"
break
# 如果没匹配到,设置一个默认或者跳过
if not ls_image_path:
print(f"在 file_list 中找不到匹配的图片名: {image_full_name}")
continue
results = []
with open(txt_path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
nums = list(map(float, line.split()))
class_id = int(nums[0])
coords = nums[1:]
# INFO: 用于随机选择
pairs = [(coords[i], coords[i+1]) for i in range(0, len(coords), 2)]
total_points = len(pairs)
if total_points > 50: # 选择 50 个点
step = total_points // 50
selected_pairs = pairs[::step] # 切片操作,按步长取点
else:
selected_pairs = pairs
flattened_selected = [coord for pair in selected_pairs for coord in pair]
points = []
# YOLO 的坐标通常是归一化坐标(0~1),需要乘以图像对应维度再转化为百分比
for i in range(0, len(flattened_selected), 2):
x_norm = flattened_selected[i]
y_norm = flattened_selected[i + 1]
# 转换为图像的实际像素坐标
x_pixel = x_norm * width
y_pixel = y_norm * height
# 转换为 Label Studio 要求的 0-100 比例坐标
x_ls = (x_pixel / width) * 100
y_ls = (y_pixel / height) * 100
points.append([x_ls, y_ls])
label_name = CLASS_MAP.get(class_id, str(class_id))
result = {
"from_name": FROM_NAME,
"to_name": TO_NAME,
"type": "polygonlabels",
"value": {
"polygonlabels": [label_name],
"points": points
}
}
results.append(result)
task = {
"data": {
"image": ls_image_path
},
"predictions": [
{
"model_version": "yolo-seg",
"result": results
}
]
}
tasks.append(task)
# 保存
with open(OUTPUT_JSON, "w", encoding="utf-8") as f:
json.dump(tasks, f, ensure_ascii=False, indent=2)
print(f"转换完成: {OUTPUT_JSON}")
执行后生成 “labelstudio_import.json” 文件,这个就是要导入的文件。
2.4. 导入结果
首先选中所有文件,选择 “Delete Tasks”,如下图:
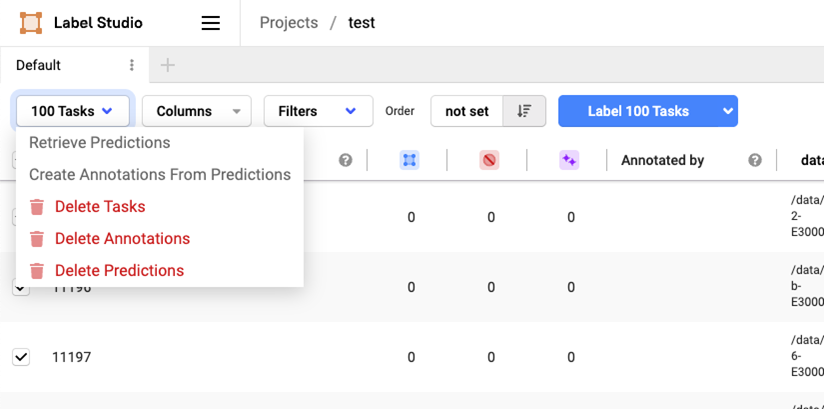
删除后,再选择 import 刚生成的文件,如下图:
此时,数据导入完成。进到标注页面如下: