1. 概述
对于一个搜索系统来说,通常采用的召回都是基于倒排索引的召回,简单来说就是需要对item侧建立倒排索引,在检索的过程中,对query分词,根据分词结果去倒排索引中查找词匹配的item,简单的流程如下图所示:
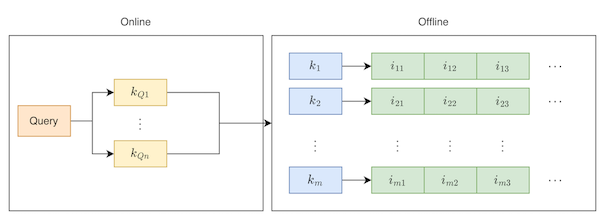
在传统的检索过程中,通常存在语义上的问题,比如Query为“连衣裙”,此时根据词匹配就检索不到核心词为“长裙”的item,为了解决这样的问题,需要对Query进行扩展,将其扩展成相似的query,以此来实现语义匹配的问题。当然,词匹配的方式的一大优势就是相关性解决的比较好。为了能从算法上解决语义的gap,双塔的召回结构是现如今较多采用的一种方法。
双塔的召回有如下的一些优势:
- item侧可离线计算,线上可采用基于ANN的向量匹配方式较快的查找到向量空间与Query相匹配的item
- 基于模型的方法,可以融入更多的特征
双塔模型的第二点优势就可以方便的对模型的特征进行扩充,尤其现如今对多模态的研究,Que2Search[1]中就是提出使用多模态的方法来训练双塔模型,同时,在Que2Search的item塔中引入了分类的任务,与上面的双塔任务共同构成了多任务的训练方式。
2. Que2Search模型
2.1. Que2Search的模型结构
Que2Search的模型结构如下图所示:

左侧是一个Query侧的塔,右侧是item侧的塔。
2.2. Query塔
Query塔侧的模型的输入特征有三部分,分别为:
-
Query文本的tri-gram。通过size=3的滑动窗口,得到tri-gram,过hash函数(如MurmurHash)后得到对应的ids,再经过Embedding后得到每个id的向量表示,最终对所有向量做sum-pooling;
-
用户所在国家。该特征是单分类的特征,也是经过Embedding后表示成向量;
-
Query原始文本。经过一个两层的XLM模型编码,取
[CLS]对应的向量作为query的语义表示;
注:XLM模型就是一个基于Transformer的语言模型,类似于BERT。
至此,我们得到了3个向量,如何将这3个向量fuse成一个向量,文中也提出了两种方式,分别为concat和attention。实验结果显示attention的结果要优于concat,假设表示个不同来源的向量,将这个向量concat在一起,得到:
计算attention的权重:
其中,,最后得到最终的合并向量表示:。
这里的是通过concat多个向量,也有其他的一些方法,如Attention-Based BiLSTM[2]中的计算方法。
2.3. Item塔
Item塔侧的模型的输入特征有五部分,分别为:
-
商品标题。使用6层XLM-R编码;
-
商品描述。与商品标题一样,使用6层XLM-R编码;
-
商品标题的tri-gram。处理方法同query侧的tri-gram;
-
商品描述的tri-gram。处理方法同query侧的tri-gram;
-
图像表示:对于每一个商品,都会附带一些图片,通过预训练模型得到图像表示,然后过MLP和Deep set方法对多个图像表示进行融合得到一个向量表示。
多个不同来源的向量通过与上述Query塔一样的Attention的方法得倒最终的向量表示。为了能对item塔的模型更好的学习,因此在这里设置了多标签多类目的分类任务,如上图中的右侧。
2.4. 样本选择
对于双塔模型来说,一般选择点击的样本作为正样本,但是在Que2Search中,选择的正样本需满足以下四个条件:
- 用户发起一次搜索
- 点击一个商品
- 给卖家留言
- 卖家回复
只有同时满足这四个条件的query和item才能成为正样本。
负样本的选择是双塔召回模型的精髓。对于负样本通常有两种策略:
- 根据频次从全库中随机采样
- batch内的随机采样
这是随机样本的部分,通常还会增加一些困难样本,主要有人工的挖掘以及在线的困难样本挖掘。在Que2Search中随机样本是采用的Batch内的负样本,假设batch的大小为,经过query塔后,query侧的向量为,同理,item侧的向量为,且向量的维度为。计算每一个query与item的cosine相似度矩阵,便得到,这里只有时是正样本,其他的为负样本,如下图所示:
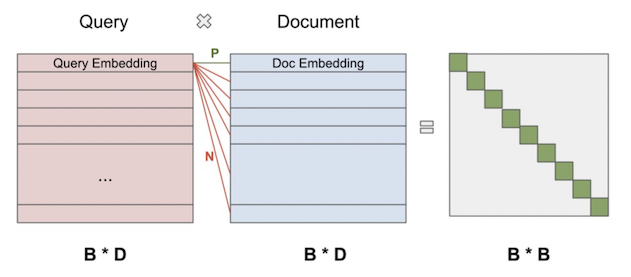
对于最后的矩阵,只有对角线上的为正样本,选择一行来看,这是一个多分类的问题,类别数为。对于该多分类,损失函数为:
其中,为缩放系数,在文章中指出在15和20之间。
缩放系数实际上就是温度系数。
在文章中还提出了另一种对称的损失函数,上述的损失函数以query为主导,另外一部分以item为主导,基于此便有了对称的损失函数:
不过实验表明在实际的线上并没有多大的收益。
除了上述的随机样本,还需要困难样本,在Que2Search中使用的是在线困难负样本挖掘,其方法是选择Batch内除了正样本以外所有负样本中相似度最高的样本作为困难负样本:
这样就构造了正负样本的集合。
但是在Que2Search中,使用了两个阶段的训练:
- 第一阶段只使用随机负样本,通过多分类的交叉熵损失函数;
- 第二阶段只使用困难负样本,损失函数却是margin rank loss效果更好。
margin rank loss为:
margin的值在0.1和0.2之间最好。
3. 总结
在Que2Search中,主要是加入了更多的文本特征,并利用基于Transformer的方法提取文本语义信息,同时在特征中融入了图像的特征,实现了多模态的模型学习。另一方面,在训练的过程中提出了多任务的学习,有利于对item塔的模型学习。
参考文献
[1] Liu Y, Rangadurai K, He Y, et al. Que2Search: fast and accurate query and document understanding for search at Facebook[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021: 3376-3384.