1. 基于图像的文字识别
基于图像的文字识别有个比较响亮的名字叫 OCR,OCR(Optical Character Recognition,光学字符识别)是一种将图像中的文字转换为可编辑文本的技术。它广泛应用于文档数字化、图片内容提取、身份证识别、车牌识别等多个领域。通过 OCR 技术,我们可以将纸质文档、扫描件、图片等中的文字信息提取出来,转换为电子文本,便于存储、编辑和分析。例如对于如下的车牌[1]:

对于这样的车牌的图像,通过 OCR 系统,识别到文字“皖AD09819”。传统的 OCR 方法通常试图对图像中的每个字符切分,再对每个字符分类,这样的方案不仅费时费力,而且效果上也很难得到保证。得益于深度学习在图像领域的深入发展,自然而然是不是存在端到端的方案实现 OCR。本文将要介绍的是基于深度学习的端到端的文字识别算法 CRNN[2]。
2. CRNN 算法的基本原理
2.1. CRNN 的网络结构
CRNN 全称为 Convolutional Recurrent Neural Network,可以实现端到端地对不定长文本序列进行识别,其主要特点是不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,简单来讲就是讲图像转换成一个序列,再对序列进行学习,分类得到最终的文字。为了实现上述的这样的功能,在 CRNN 模型中包括三个部分,分别称作卷积层(Convolutional Layers)、循环层(Recurrent Layers)以及转录层(Transcription Layers),其网络结构如下所示:
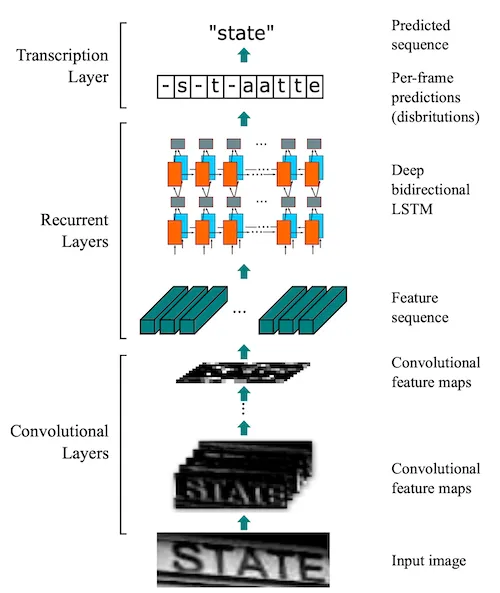
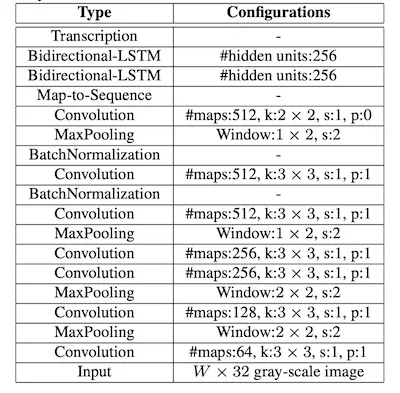
其中,卷积层是由 CNN 构成,其主要作用是从输入的图像中提取特征,并将提取的特征图输入到循环层中,循环层是由双向的 LSTM 构成的,它将输出对特征序列每一帧的预测。最后转录层将得到的预测概率分布转换成标记序列,得到最终的识别结果,它实际上就是模型中的损失函数。在原论文[2]中也给出了详细的网络结构图:
2.1.1. 卷积层
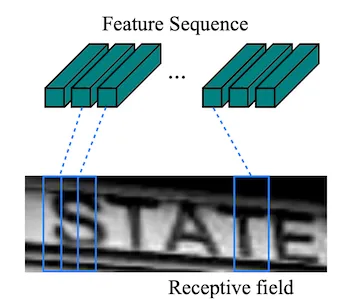
CRNN 中的卷积层与卷积神经网络中的操作没有什么差别,对于这部分不了解的,可以参见文章《卷积神经网络VGG》[3]。在 CRNN 中的卷积层也是由一系列的卷积层、池化层、BN 层构成。从卷积神经网络的理论可以知道,经过卷积层输出的特征图中每个像素与原图存在一定的对应关系,这种对应关系也称为感受野,在原论文[2]中也给出了这种关系的示意图,如下所示:
2.1.2. 循环层
在 CRNN 模型中,紧跟在卷积层之后的是循环层,用于处理卷积层提取的特征序列,在原文[2]中使用的是双向的 LSTM:
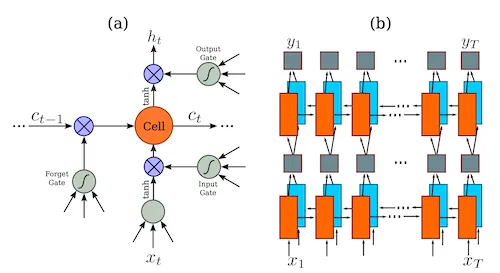
对于更多的有关 LSTM 的介绍,可以参见《长短期记忆网络LSTM》[4]。
2.1.3. 转录层
转录层的作用是将前面通过卷积层和循环层得到的预测序列转换成标记序列,并得到最终的识别结果。在 CRNN 中的转录算法使用的是 CTC (Connectionist Temporal Classification)算法,简单来讲就是 CTC 能够实现一种序列到另一种序列的转换,如在上面图像经过卷积层和循环层后得到一种序列,我们最终希望得到的是文字,这是另一种序列,在这转换的过程中,CTC 起到了转码和对齐的作用。这一块也是整个 CRNN 网络中的难点。
2.2. CTC 算法
正如上面所述,CTC 能够实现从一种序列转换成另一种序列,而在这转换的过程中起到了转码+对齐的作用,具体是如何实现的呢?我们以一个简单的 OCR 的例子开始,假设经过卷积层和循环层后时间序列经过解码的结果如下:
| 时间步 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 输出 | H | H | - | E | E | L | - | L | - | O | - |
其中,“-” 表示 CTC 中的 blank,即“无字符”的意思。CTC 从上述的输出中,解码出最终的输出序列需要经过以下两步:
- 删除相邻的重复字符,得到“H-EL-L-O-”
- 移除 blank(空白)标签,得到“HELLO”
以上便是通过 CTC 算法从序列预测结果得到最终的结果的过程,那么在 CRNN 的模型训练过程中是如何做到的?对于模型的训练来说,目标函数(loss function)是用来指导模型如何更新参数的唯一指标,而目标函数则定义了模型的“输出”和“目标标签”之间的差距。那么对于从一种序列转换到另一种序列这种情况来说,假设上述的“HH-EEL-L-O-”是一条路径,那么“-H-EEL-L-O-”也是一条合法的路径,也就是说同样的目标标签“HELLO”存在多种路径的结果与之对应。
对于输入 ,标签序列为 ,我们希望在输入为 的时候模型预测输出为 的概率 越大越好,
由上述的分析可以知道,同样的输入为 的情况下,得到输出为 的路径会有很多条,定义 为所有路径上模型预测输出 的总概率:
其中, 为其中一条路径, 为所有能转录成标签 的路径集合,而 则表示路径的概率:
举个简单的例子,假设目标标签是“AB”,时间步为 3:
| 时间步 | A | B | blank |
|---|---|---|---|
| t=1 | 0.6 | 0.2 | 0.2 |
| t=2 | 0.5 | 0.3 | 0.2 |
| t=3 | 0.1 | 0.8 | 0.1 |
那么合理的路径有“AB-”,“A-B”,“-AB”,“AAB”,“ABB”,那么 :
至此,我们对 CTC 的计算方法有了基本的了解,这对于理解 CRNN 算法已经足够,同时,PyTorch 等库已经内置了 CTC,例如在 PyTorch 中的 nn.CTCLoss[5]:
ctc_loss = nn.CTCLoss(
blank=0, # 空白标签的索引(默认为0)
reduction='mean', # 损失聚合方式('none'、'sum'、'mean')
zero_infinity=False # 是否将无限损失归零(长序列建议True)
)
对于 CTC 损失函数的计算,则会使用到所谓的 log-sum-exp 技巧,这部分内容就不在本篇文章中介绍。
3. 车牌识别的 PyTorch 实践
3.1. 数据集
当前实验的数据集来自 PaddlePaddle[1],我们选择了 CCPD2020.tar,同时将其中的 train 文件和 val 文件夹合并,因此验证集会在训练的过程中自动选择,构建数据集的代码如下:
class LprData(Dataset):
def __init__(self, root_path):
self.root_path = root_path
self.images = sorted([root_path + "/train/" + i for i in os.listdir(root_path + "/train/")])
self.label_dict = self._parse_label(root_path + "/rec.txt")
self.transform_img = transforms.Compose([
transforms.Resize((32, 160)),
transforms.ToTensor()
])
def __getitem__(self, index):
img = Image.open(self.images[index]).convert("RGB")
img_name = self.images[index].strip().split("/")[-1]
label = self.label_dict[img_name]
label = torch.tensor(label, dtype=torch.long)
return self.transform_img(img), label, len(label)
def _parse_label(self, label_file):
f = open(label_file)
label_dict = {}
for line in f.readlines():
lines = line.strip().split("\t")
assert(len(lines) == 2)
img_name = lines[0].strip().split("/")[-1]
label = lines[1].strip()
label_pred_list = []
for x in label:
label_pred_list.append(CHARS_DICT[x])
label_dict[img_name] = label_pred_list
f.close()
return label_dict
def __len__(self):
return len(self.images)
在这里,需要使用到将字符和 index 对应的 CHARS_DICT,这里也是参考了 LPRNet[6],详细的代码如下:
CHARS = ['京', '沪', '津', '渝', '冀', '晋', '蒙', '辽', '吉', '黑',
'苏', '浙', '皖', '闽', '赣', '鲁', '豫', '鄂', '湘', '粤',
'桂', '琼', '川', '贵', '云', '藏', '陕', '甘', '青', '宁',
'新',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K',
'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V',
'W', 'X', 'Y', 'Z', 'I', 'O', '-'
]
CHARS_DICT = {char:i for i, char in enumerate(CHARS)}
3.2. 构建模型
在此,基本还原原论文[2]中的网络结构,但也存在些许个人的修改,具体见代码:
class BidirectionalLSTM(nn.Module):
def __init__(self, nIn, nHidden, nOut):
super().__init__()
self.lstm = nn.LSTM(nIn, nHidden, bidirectional=True, batch_first=True)
self.fc = nn.Linear(nHidden * 2, nOut)
def forward(self, input):
lstm, _ = self.lstm(input)
output = self.fc(lstm)
return output
class CRNNModel(nn.Module):
def __init__(self, in_channels=3, hidden_size=256, nclass=68):
super().__init__()
self.cnn = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(1,2), stride=2),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(1,2), stride=(2,1)),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=2, stride=1, padding=0),
nn.BatchNorm2d(num_features=512),
nn.ReLU(inplace=True)
)
self.rnn = nn.Sequential(
BidirectionalLSTM(512, hidden_size, hidden_size),
BidirectionalLSTM(hidden_size, hidden_size, nclass))
def forward(self, input):
conv = self.cnn(input)
_, _, h, _ = conv.size()
assert h == 1
conv = conv.squeeze(2) # [B, C, W]
conv = conv.permute(0, 2, 1) # [B, W, C]
output = self.rnn(conv)
return output
通过 torchinfo.summary() 函数,我们打印出 CRNN 的网络结构:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
CRNNModel [1, 18, 68] 3,188,804
├─Sequential: 1-1 [1, 512, 1, 18] --
│ └─Conv2d: 2-1 [1, 64, 32, 160] 1,792
│ └─BatchNorm2d: 2-2 [1, 64, 32, 160] 128
│ └─ReLU: 2-3 [1, 64, 32, 160] --
│ └─MaxPool2d: 2-4 [1, 64, 16, 80] --
│ └─Conv2d: 2-5 [1, 128, 16, 80] 73,856
│ └─BatchNorm2d: 2-6 [1, 128, 16, 80] 256
│ └─ReLU: 2-7 [1, 128, 16, 80] --
│ └─MaxPool2d: 2-8 [1, 128, 8, 40] --
│ └─Conv2d: 2-9 [1, 256, 8, 40] 295,168
│ └─BatchNorm2d: 2-10 [1, 256, 8, 40] 512
│ └─ReLU: 2-11 [1, 256, 8, 40] --
│ └─Conv2d: 2-12 [1, 256, 8, 40] 590,080
│ └─BatchNorm2d: 2-13 [1, 256, 8, 40] 512
│ └─ReLU: 2-14 [1, 256, 8, 40] --
│ └─MaxPool2d: 2-15 [1, 256, 4, 20] --
│ └─Conv2d: 2-16 [1, 512, 4, 20] 1,180,160
│ └─BatchNorm2d: 2-17 [1, 512, 4, 20] 1,024
│ └─ReLU: 2-18 [1, 512, 4, 20] --
│ └─Conv2d: 2-19 [1, 512, 4, 20] 2,359,808
│ └─BatchNorm2d: 2-20 [1, 512, 4, 20] 1,024
│ └─ReLU: 2-21 [1, 512, 4, 20] --
│ └─MaxPool2d: 2-22 [1, 512, 2, 19] --
│ └─Conv2d: 2-23 [1, 512, 1, 18] 1,049,088
│ └─BatchNorm2d: 2-24 [1, 512, 1, 18] 1,024
│ └─ReLU: 2-25 [1, 512, 1, 18] --
├─Sequential: 1-2 [1, 18, 68] --
│ └─BidirectionalLSTM: 2-26 [1, 18, 256] --
│ │ └─LSTM: 3-1 [1, 18, 512] 1,576,960
│ │ └─Linear: 3-2 [1, 18, 256] 131,328
│ └─BidirectionalLSTM: 2-27 [1, 18, 68] --
│ │ └─LSTM: 3-3 [1, 18, 512] 1,052,672
│ │ └─Linear: 3-4 [1, 18, 68] 34,884
==========================================================================================
Total params: 11,539,080
Trainable params: 11,539,080
Non-trainable params: 0
Total mult-adds (M): 736.58
==========================================================================================
Input size (MB): 0.06
Forward/backward pass size (MB): 12.14
Params size (MB): 33.40
Estimated Total Size (MB): 45.60
==========================================================================================
注意:
- 这里在
ReLU: 2-25步骤,h 的维度正好是 1;- 时间步在上述模型中是 18,而数据集中车牌的长度是 8,时间步和目标标签的长度关系是 ,其中, 为时间步, 为目标标签的长度
在构建模型的过程中,在堆叠双向 LSTM 的过程中,分别使用了上述的自行封装的方式,另外还尝试了如下的代码:
self.bi_lstm = nn.LSTM(
input_size=512, # 按照上面CNN下采样比例计算
hidden_size=hidden_size,
num_layers=2,
bidirectional=True,
batch_first=True
)
self.fc = nn.Linear(in_features=hidden_size*2, out_features=nclass)
通过 nn.LSTM 函数的 num_layers 参数设置堆叠的层数,两者的差别就在于层与层之间缺少了 nn.Linear,也正是因为这个,导致了在后续的训练过程中效果便得较差。
3.3. 模型的训练
训练的详细代码如下:
class CRNN:
def __init__(self, WORKING_DIR=None):
self.WORKING_DIR = WORKING_DIR
def train(self):
# 1. 加载数据,拆分训练集和验证集
train_dataset = LprData(self.WORKING_DIR)
generator = torch.Generator().manual_seed(25)
train_dataset, val_dataset = random_split(train_dataset, [0.8, 0.2], generator=generator)
device = "cuda" if torch.cuda.is_available() else "cpu"
num_workers = 0
if device == "cuda":
num_workers = torch.cuda.device_count() * 4
BATCH_SIZE = 16
train_dataloader = DataLoader(dataset=train_dataset,
num_workers=num_workers,
pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True)
val_dataloader = DataLoader(dataset=val_dataset,
num_workers=num_workers,
pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True)
# 定义模型
model = CRNNModel()
model = model.to(device)
# INFO: 设计模型参
optimizer = optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-4)
# INFO: 损失函数
ctc_loss = nn.CTCLoss(blank=len(CHARS)-1, reduction='mean') # reduction: 'none' | 'mean' | 'sum'
EPOCHS = 500
train_losses = []
val_losses = []
best_val = float('inf')
for epoch in tqdm(range(EPOCHS), desc="EPOCHS", leave=True):
model.train()
train_running_loss = 0
for idx, images_targets in enumerate(tqdm(train_dataloader, desc="Training", leave=True)):
target_lengths = tuple([l for l in images_targets[2]])
input_lengths = tuple([18 for l in images_targets[2]])
images = images_targets[0].float().to(device)
labels = images_targets[1].to(device)
logits = model(images) # N, T, C
optimizer.zero_grad()
log_probs = logits.permute(1, 0, 2)
log_probs = nn.functional.log_softmax(log_probs, dim=2)
loss = ctc_loss(log_probs, labels, input_lengths=input_lengths, target_lengths=target_lengths)
train_running_loss += loss.item()
loss.backward()
optimizer.step()
train_loss = train_running_loss/(idx + 1)
train_losses.append(train_loss)
model.eval()
val_running_loss = 0
with torch.no_grad():
for idx, images_targets in enumerate(tqdm(val_dataloader, desc="Validation", leave=True)):
target_lengths = tuple([l for l in images_targets[2]])
input_lengths = tuple([18 for l in images_targets[2]])
images = images_targets[0].float().to(device)
labels = images_targets[1].to(device)
logits = model(images) # N, T, C
log_probs = logits.permute(1, 0, 2)
log_probs = nn.functional.log_softmax(log_probs, dim=2)
loss = ctc_loss(log_probs, labels, input_lengths=input_lengths, target_lengths=target_lengths)
val_running_loss += loss.item()
val_loss = val_running_loss
if val_loss < best_val:
best_val = val_loss
torch.save(model.state_dict(), 'best_crnn.pth')
val_losses.append(val_loss)
# INFO: 记录
EPOCHS_plot = []
train_losses_plot = []
val_losses_plot = []
for i in range(0, EPOCHS, 5):
EPOCHS_plot.append(i)
train_losses_plot.append(train_losses[i])
val_losses_plot.append(val_losses[i])
print(f"EPOCHS_plot: {EPOCHS_plot}")
print(f"train_losses_plot: {train_losses_plot}")
plot_losses(EPOCHS_plot, train_losses_plot, val_losses_plot, "crnn_train_val_losses.jpg")
注意,在训练的过程切勿使用 SGD 作为优化器,这会导致训练出的模型只能正确预测前面部分的文字,后面的所有文字都变成空白符。这个问题排查了很久,基本结论是 SGD 在 CTC 中容易陷入 early alignment,最终,切换到 AdamW 优化器后就变正常了。
在训练的过程中,我们也记录了损失函数的变化:
3.4. 模型的预测
根据 CTC 的计算步骤,这里采用贪婪的解码策略,有如下推理过程:
def __inference(self, tensor_image, model):
# 开始推理
model.eval()
with torch.inference_mode():
# 增加 batch 维度
pred = model(tensor_image.unsqueeze(0))
# 取消 batch 维度
log_probs = pred.permute(1, 0, 2)
log_probs = nn.functional.log_softmax(log_probs, dim=2)
log_probs = log_probs.squeeze(1)
log_probs = log_probs.cpu().detach().numpy()
# 使用 greedy decode
final_pred_list = []
# 所有都通过 greedy 方式求得最大值
for i in range(len(log_probs)):
final_pred_list.append(np.argmax(log_probs[i]))
assert(len(final_pred_list) >= 1)
no_repeat_blank_final_list = []
pre_c = final_pred_list[0]
if pre_c != len(CHARS) - 1:
no_repeat_blank_final_list.append(pre_c)
# 去除相同的预测
for c in final_pred_list:
if (pre_c == c) or (c == len(CHARS) - 1):
if c == len(CHARS) - 1:
pre_c = c
continue
no_repeat_blank_final_list.append(c)
pre_c = c
final_char = []
for i, x in enumerate(no_repeat_blank_final_list):
final_char.append(CHARS[x])
# print("".join(final_char))
return "".join(final_char)
def predict(self, img_list, model_path):
transform = transforms.Compose([
transforms.Resize((32, 160)),
transforms.ToTensor()])
device = "cuda" if torch.cuda.is_available() else "cpu"
model = CRNNModel().to(device)
model.load_state_dict(torch.load(model_path,
map_location=torch.device(device),
weights_only=True))
final_pred = []
for img in img_list:
tensor_image = transform(img)
tensor_image = tensor_image.float().to(device)
final_char = self._inference(tensor_image, model)
print(final_char)
final_pred.append(final_char)
return final_pred
最终在上述的 test 文件夹的数据测试的准确率为 87%,通过分析发现,数据集中的很多图片并非清晰的,这也限制了模型的准确率,另外,模型的构建中还是为了还原原论文,针对不同的问题,可以设计更加复杂的模型结构,进一步提升模型的效果。
4. 总结
在 CRNN 的网络结构中包含了三个组成部分,分别为卷积层,循环层和转录层,而至关重要的是转录层。在转录层中不得不提的便是 CTC 算法,文中也知识对 CTC 算法做了简要的概述,通过实验过程,可以发现,在具体的实现的过程中仍然存在很多的 tricks,但不得不提的是,模型的大小确实很小。不得不让人惊叹如此小的模型能有如此的效果。
参考文献
[1] https://aistudio.baidu.com/datasetdetail/175158/0
[2] Shi B, Bai X, Yao C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2016, 39(11): 2298-2304.
[3] http://felixzhao.cn/articles/article/41
[4] http://felixzhao.cn/articles/article/7
[5] https://docs.pytorch.org/docs/stable/generated/torch.nn.CTCLoss.html
[6] https://github.com/sirius-ai/LPRNet_Pytorch/blob/master/data/load_data.py